Slack experienced meteoric growth between 2017 and 2020—but that level of growth came with growing pains. In his talk at the 2021 o11ycon+hnycon, Frank Chen (LinkedIn), a Slack Senior Staff Engineer, detailed one of Slack’s biggest pain points in that period: flaky tests.
A flaky test returns both a passing and failing result despite no changes in the code. At one point, between 2017 and 2020, Slack’s flaky test rate reached as high as 50%. This amount of flakiness led to huge problems when it came to the DevOps practice of continuous integration (CI), where developers frequently integrate code into a central repository.
As a result, developers’ trust in tests was declining, developer velocity was starting to become sluggish, and huge incidents like a “large and cursed” Jenkins queue (as Frank described it) were starting to crop up.
So Frank set out to find a solution by using observability to trace Slack’s CI logic. Once fully implemented, Frank’s approach helped reduce the rate of flaky tests per pull request (PR) down to 5%—a 10x reduction. Flakiness rate per PR—consisting of individual commits and up to hundreds of tests—became a guiding service level objective (SLO) to understand and improve the CI user experience. Here’s how he did it.
Slack’s growth led to sluggishness and flakiness
From 2017 to 2020, Slack evolved from a single web app with a monorepo to what Frank describes as “a topology of many languages, services, and clients that serve different needs.” Most internal tools were built quickly and could scale just enough to keep up. Those same limitations also applied to CI infrastructure, which was originally built by the CTO and a handful of early Slack employees.
At around 7 minutes into his talk, Frank provided a rough overview of Slacks’s CI infrastructure from local branch development to testing. The Slack team found that, with a 10% month-over-month growth in test execution count, this CI infrastructure was starting to buckle.
As the rate of flaky tests started to reach 50%, Slack’s internal tools teams started to hear two main complaints:
- It is slow. According to Frank, slowness is the hardest problem to debug in distributed systems.
- It is flaky. Which erodes developer trust in the efficacy of the system.
To try and understand what was happening and why, the internal tools team at Slack got to work devising their own tracing solution, which Frank was later able to apply to the old CI system.
Slack’s tracing solution: SpanEvents, SlackTrace, and Honeycomb
Suman Karumuri, Frank’s mentor and lead on the observability team at Slack, pioneered the development of Slack’s tracing solution, which includes a new data structure called a SpanEvent, an in-house solution called SlackTrace, and Honeycomb.
Suman did a full write-up here, which Frank recommends. Frank summarized Suman’s approach into three points:
- First, Slack implemented a SpanEvent structure that allows them to create an event once and use it in multiple places.
- Then, Suman’s SlackTrace pipeline can ingest SpanEvents from multiple clients, allowing the Slack team to create views from the same data model by processing it through Kafka.
- Users can then access and analyze SpanEvents through a data warehouse or a real-time store, like Honeycomb.
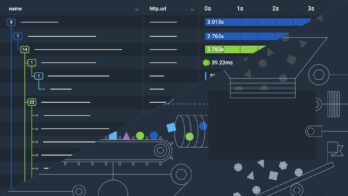
Suman explained in his article that with this setup, Slack used their data warehouse with Presto to perform complex queries and used Honeycomb to address issues in real time. In fact, their real-time store can provide access to trace data with a latency of fewer than 5 seconds.
Honeycomb helps the team at Slack visualize and analyze this real-time trace data. Frank’s innovation is applying that same setup and benefit to CI, thereby enabling teams to quickly identify issues that address both sluggishness and flakiness.
How Frank applied tracing & observability to Slack’s CI
The CI infrastructure Frank inherited remained mostly unchanged for four years from when it was established. By applying tracing to Slack’s CI infrastructure, Frank was able to transform it, one Honeycomb-powered triage at a time.
Step 1: Frank started small
Shortly after joining Slack, Frank had a conversation with Suman about SlackTrace. From that exchange, Frank was inspired to take the afternoon and create a quick prototype with their test runner.
During the PR rollout and a few simulated test runs, starting small allowed the team to rack up some quick wins. Frank noticed that a Git checkout step was performing slowly for a specific portion of their fleet. Using Honeycomb, they could see that a few instances within the auto-scaling group of underlying instances were not being updated. Knowing exactly where the problem was occuring, they were able to fix it quickly and easily.
Building on that momentum, Frank focused on gaining a full understanding of their entire CI process. “One way I was able to understand how the pieces fit together was by using tracing to put in easy, small flags to understand,” he explained. “If we change how we initialize this part of our QA setup, does that affect anything else in that codebase?”
Frank was responsible for getting buy-in from relevant stakeholders. Racking up quick wins is a great way to get momentum going and make iterative progress, but every once in a while a big, highly visible opportunity comes along, as we’ll see.
Step 2: Tackling the “Jenkins Queue, Large and Cursed”
A few months after his initial afternoon prototype, the turning point came for Frank on day two of a multi-day, multi-team incident. Frank described the situation as the “Jenkins Queue, Large and Cursed”:
“Day one, our teams were scrambling with one-off hacks to try to bring a few overloaded systems under control. On the morning of day two, I added our first cross-service trace by reusing the same instrumentation from our test runner.
Very quickly, with Honeycomb’s BubbleUp, it became clear where problems were coming from. On a portion of the fleet, we could see that Git LFS (Large File Storage) had slowed down the entire system. Over the next month, this sort of cross-system interaction led to targeted investments on how we can add this throughout Checkpoint traces.”
Specifically, Frank added traces to previously un-instrumented services at around 10 a.m. Results started streaming in through Honeycomb immediately. At around noon, Frank was able to diagnose the problem and the team could then get to work on fixing it. This quick diagnosis was only possible with Honeycomb visualizing that trace data, which one of Frank’s coworkers described as “dope as fuck.”
Step 3: Reducing flakiness with a unified effort
One of the results of Frank’s CI tracing solution was a set of shared dimensions his team could use to make queries in Honeycomb legible and accessible. These dimensions were stubbed early in a library and instrumented with a few clients. Since then, various teams have extended and reused these dimensions for their use cases, creating a shared vocabulary for Slack’s CI tracing.
With this system in place, Frank’s team has been able to triage many CI issues quickly using Honeycomb. As they fixed each issue, iterating their code along the way, Slack was able to reduce test flakiness from 50% to 5%. This reduction has had a compounding effect on developer velocity and confidence in their production systems.
Moving forward with CI tracing at Slack
The keystone in Slack’s tracing system was Honeycomb, which allowed Frank to quickly triage problems as they occurred. Over time, the series of fixes introduced (thanks to Honeycomb) not only fostered excitement and buy-in for his efforts but also fixed long-standing problems with slowness and flakiness.
The importance of this solution is not lost on Frank, as early on in his talk he quoted Uncle Ben from Spiderman, saying “With great power comes great responsibility.” To learn more about how he wielded this “great power” watch his full o11ycon+hnycon talk.
To get started with your own tracing solution, get started with Honeycomb for free today.