Effortless Engineering: Quick Tips for Crafting Prompts
Large Language Models (LLMs) are all the rage in software development, and for good reason: they provide crucial opportunities to positively enhance our software. At Honeycomb, we saw an opportunity in the form of Query Assistant, a feature that can help engineers ask questions of their systems in plain English. But we certainly encountered issues while building it—issues you’ll most likely face too if you’re building a product with LLMs—with the main one being, how do we get the model to return data in a way that works with our softwa

By: Michael Sickles

Large Language Models (LLMs) are all the rage in software development, and for good reason: they provide crucial opportunities to positively enhance our software. At Honeycomb, we saw an opportunity in the form of Query Assistant, a feature that can help engineers ask questions of their systems in plain English. But we certainly encountered issues while building it—issues you’ll most likely face too if you’re building a product with LLMs—with the main one being, how do we get the model to return data in a way that works with our software?
LLMs, by nature, are nondeterministic. That means for the exact same input, you cannot guarantee the exact same output. However, there are techniques we can leverage that will get us close enough.
This blog will walk you through building out different prompts, exploring the outputs, and optimizing them for better results. Even though we can’t guarantee outputs, we can still measure how the prompt is doing in various ways. Let’s dig in!
First things first: what is prompt engineering?
Prompt engineering is a new concept that has come out of LLMs. We carefully craft our prompt to manipulate it towards a desired output. Essentially, we give the LLM hints on what we want. It could take multiple iterations to find a prompt that works well for a given use case. It is not an exact science, and rather, it is more of an experimentation process. The hints you put in your prompt can range from asking for the data in a specific format all the way to impersonating a TV celebrity. The only guiding principle is that we can expect the result to be imperfect, but a good prompt gets us close enough.
Sofa Corporation
Let’s pretend we’re Sofa Corp, the prime seller of everything customers need to sit down and relax. We have couches and chairs in many different styles, finishes, colors, and more. We heard about LLMs, and we’d like to build an integration where our customers can describe the perfect chair that would meet all their needs, and our page returns chairs that fit our customers’ criteria.

Building our first prompt
We have a list of products, and behind the scenes, each product has tags to describe it. This can be descriptions like color, keywords (e.g., cozy), or type. We just need our LLM to return a comma-separated list of tags from a description, and the backend can filter the product list.
Here is our first simple try: we’ll generate tags from our search text description and see how it goes.
The app has a user describe the perfect chair of their dreams, and a subset of chairs should be returned that best match that description. For this example, I said I love the color purple:

It returned a purple chair! Behind the scenes, we can see the “tags” returned:
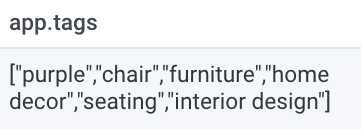
Purple is one of the tags of the product! But there is a slight problem: our prompt returned a bunch of tags that don’t really make sense.
Let’s try a different, broader prompt: I would like a chair that would be relaxing on the beach:
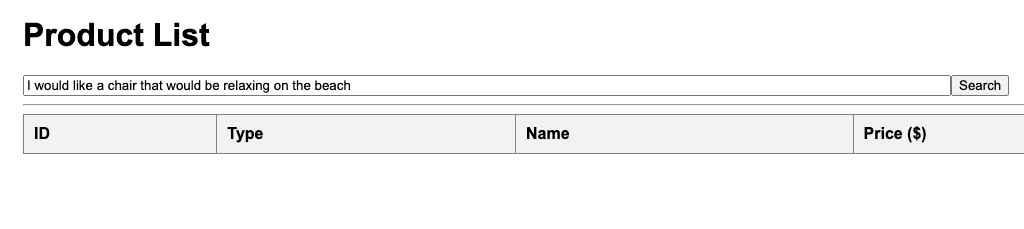
No products are returned. Below are the tags returned:
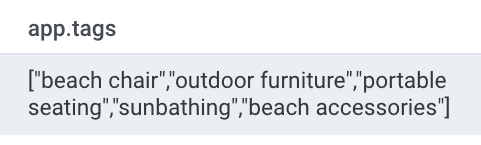
When I take a quick glance at my products, those tags don’t exist on any product. Yet, this tropical chair might have matched if our LLM knew what tags were available:

The model gave back a decent list of tags, but it doesn’t know what tags are possibly valid. That’s where prompt engineering comes in.
Prompt engineering
We can update our prompt to be a bit more specific. We are lucky that so far, our LLM is returning tags in CSV format for our code to use. LLMs throw some randomness on results, and as such, we can’t rely on it always doing this. We can, however, influence the data format and results by updating our prompt on our intent.
Adding phrases like “output tags in CSV format” will lead to better results. We can tell the model, “Here are the tags that are relevant.” That can lead to tags that we know our system has. There is a bit of downside though: commonly, LLMs will charge you for how much text you send in your response—so the more we throw in there for the perfect data structure and returns, the more it will cost us.
In a perfect world, we would have unlimited money. But the reality is we will want to optimize our prompts for cost and reliability. We’ll share ways to measure those a little bit later. For now, let’s update our prompt to output in CSV and try to pick from a list of well-known tags:

Here’s the result. Below, we can see what I searched and the tags it outputs. The search text was pretty generic, but the prompt was still able to pull relevant tags. The tags also are in our provided list!

Prompt injection attack
Since we’re taking generic text from our users, they can influence the result. Right now, there’s nothing stopping users from inputting really long sentences and eating up the token cost, or even writing nefarious things. Let’s try breaking it by telling the prompt to do something different:

In this example, it didn’t do exactly what I wanted (no “jumanji”) but it definitely did not output a valid tag. Depending on how you interact with your LLM and parse the data it returns, you have to expect users are going to do strange, and sometimes nefarious things. My code is supposed to parse the CSV result. It is a good idea to set up alerting and error catching mechanisms around the number of tags returned. I can even influence my prompt to try and return at least two tags. However, if a user comes in asking for a bicycle, they shouldn’t get any tags in response. We can update our prompt to possibly handle that case. Maybe we give examples. We can also manipulate the searchText our user is inputting. Below is an updated prompt that has examples to yield better results.

Measuring the success of our prompt
Over time, we might want to try different prompts. As a best practice, we want to find ways to measure if it’s returning results we expect it to, to see if we’re heading in the right direction.
At Honeycomb, we heavily make use of tracing and wide events. We can grab interesting bits about our object and slice and dice it in different ways.
Earlier, I showed screenshots where I put the user input text, and the tags returned, the number of tags, and the number of results from the list of products that match the tags. Ideally, we get at least two tags returned. A nice-to-have would be that when I do have tags returned, it matches some of my products. I can measure those details and alert off them or show them on dashboards. For example, if my prompt changes and I notice the filtered count is zero, that’s a sign my prompt isn’t working the way I need it to. Other useful metrics might be around errors in parsing the response, and the cost of my prompt. Remember, a longer prompt with more details might lead to more accurate results consistently but will cost more money.
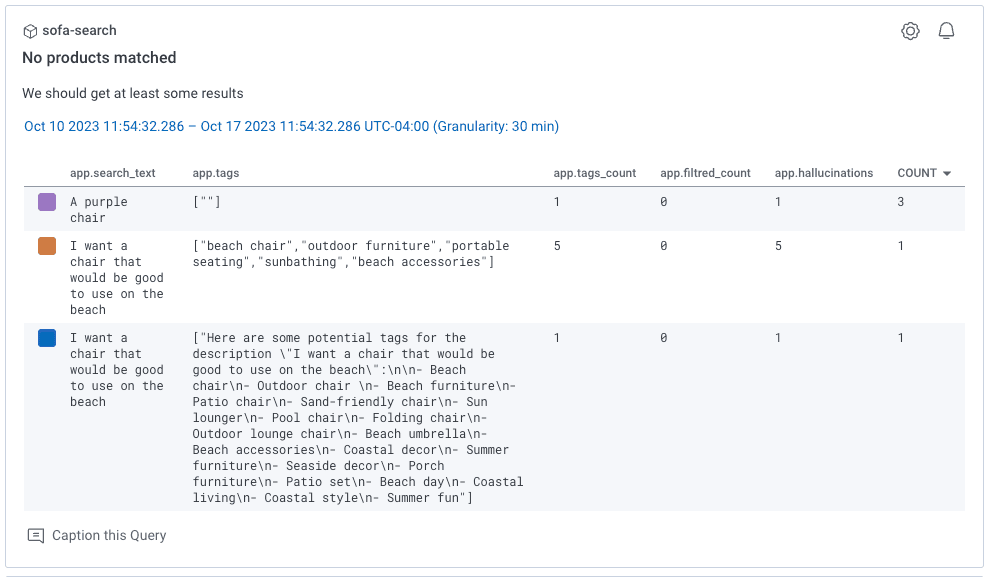
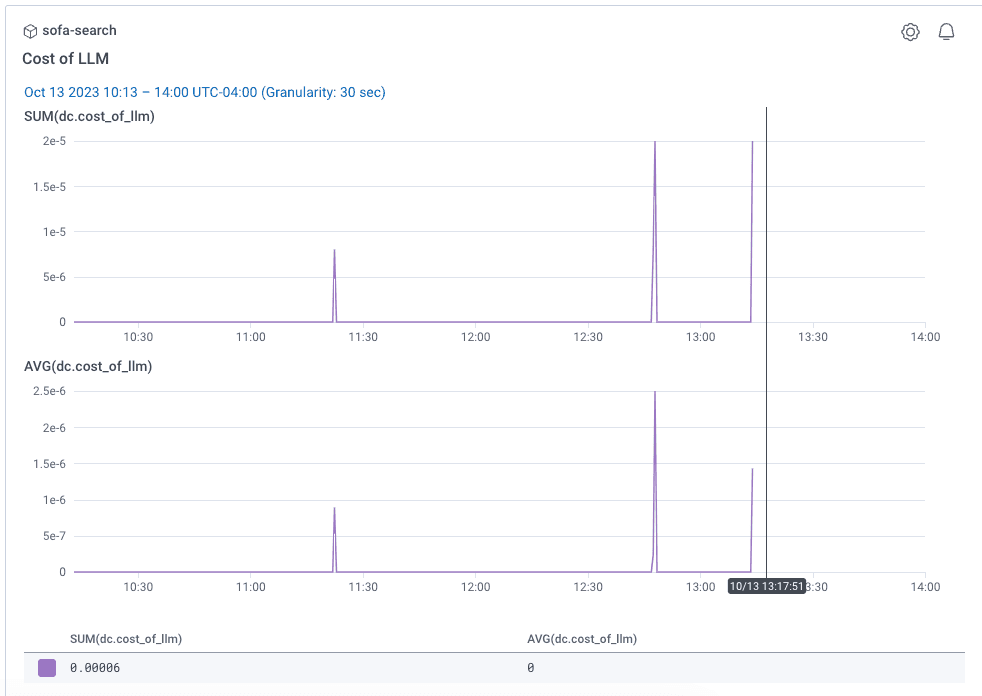
Prompt experimentation
The last bit of advice I have to offer is about quickly iterating on your prompt. By utilizing feature flags, experimentation becomes a lot easier around different prompts and LLM models. With the extra observability and A/B testing, it should be easy to understand how different prompts lead to better (or worse!) experiences. Add span attributes to describe which feature flag is served and what LLM model is used to quickly compare results and costs. Other things to try out would be limiting the searchText / user input in terms of length.
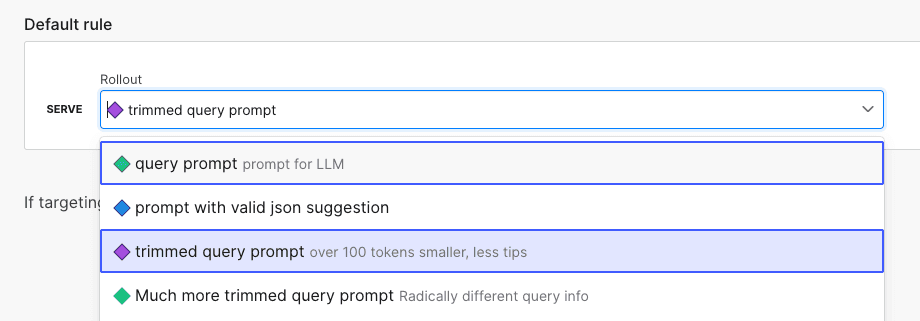
Conclusion
I hope this quick primer on prompt engineering was useful. If you’d like to learn more, you can read about our experience using LLMs in Honeycomb—Phillip mentions prompt engineering in there. You can also see all the code I used in this blog on my GitHub.
Happy prompting!
Sickles
Want to know more?
Talk to our team to arrange a custom demo or for help finding the right plan.