Virtualizing Our Storage Engine
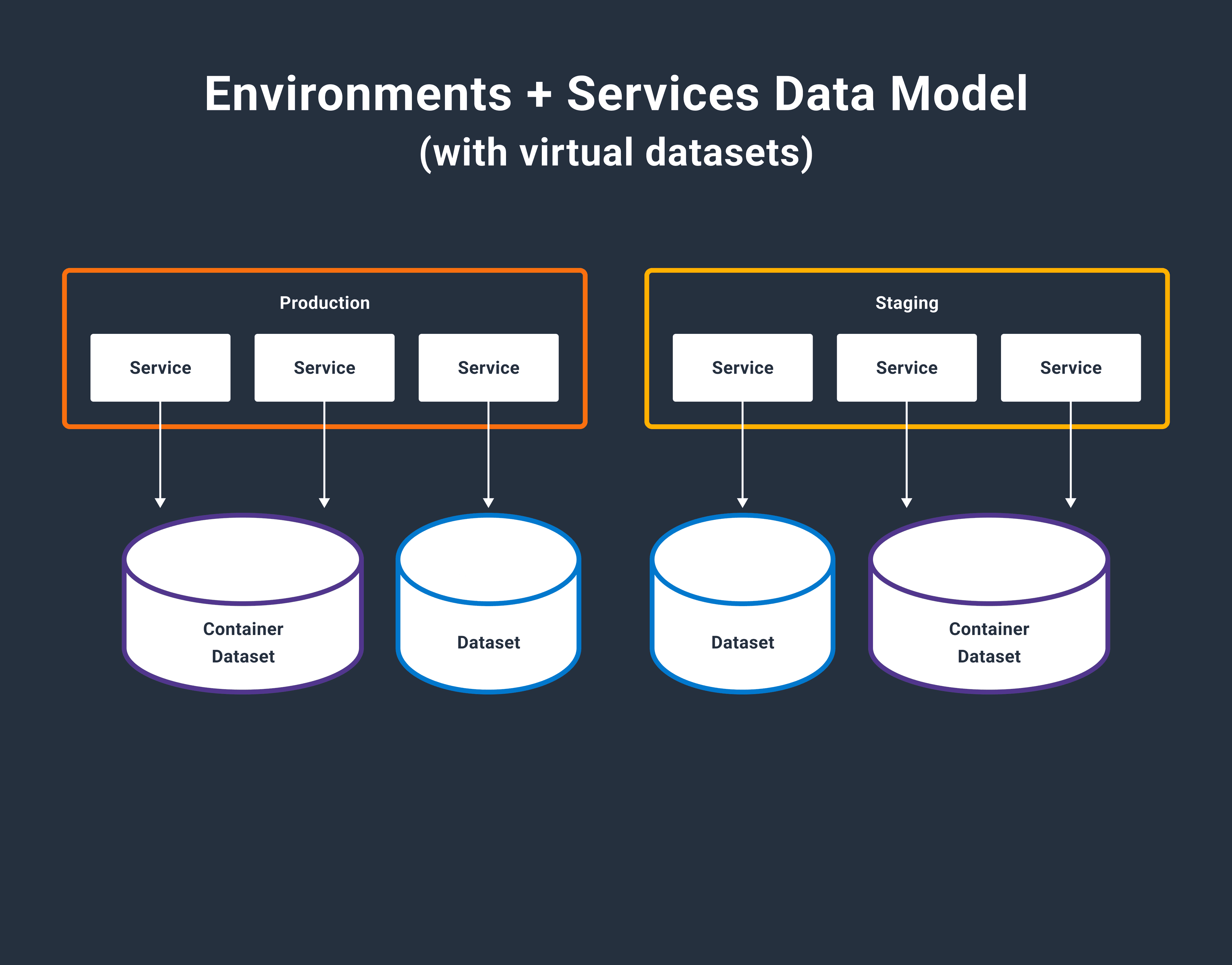
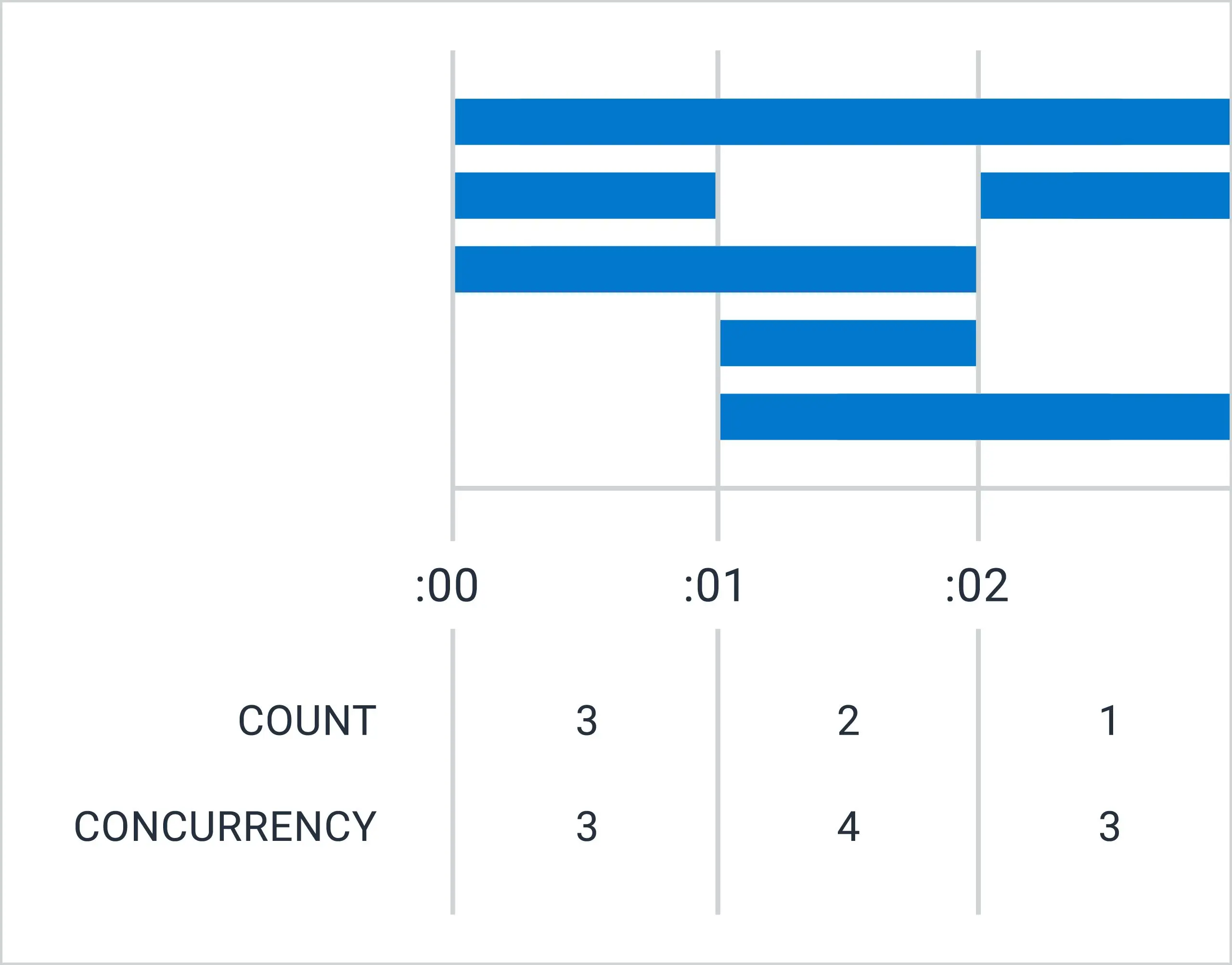
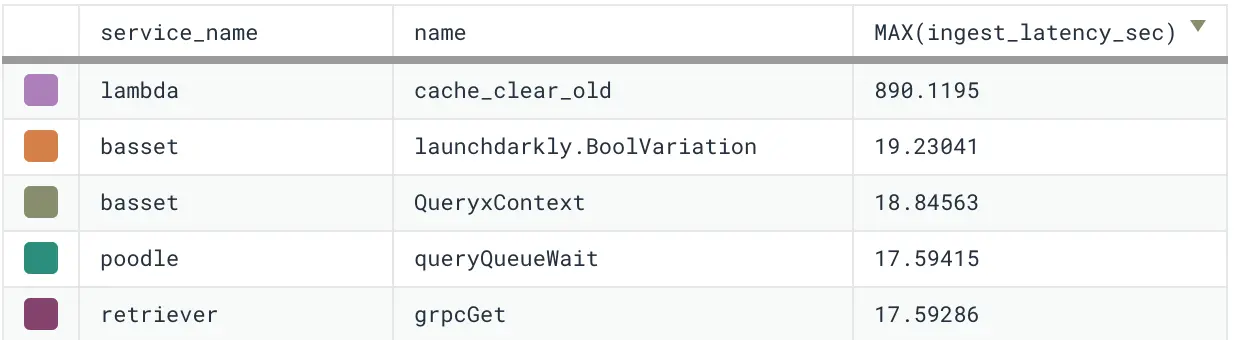
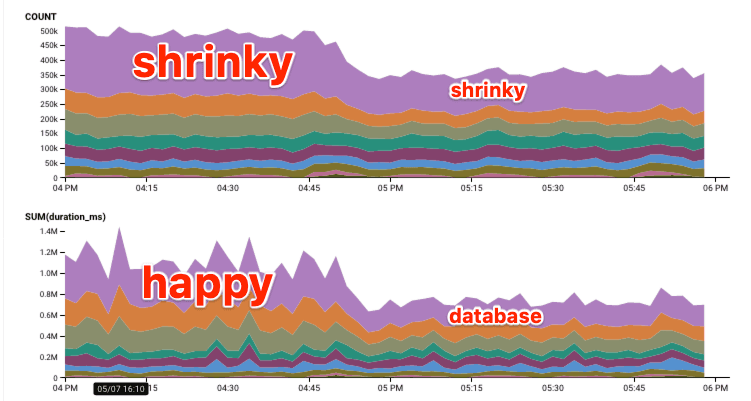
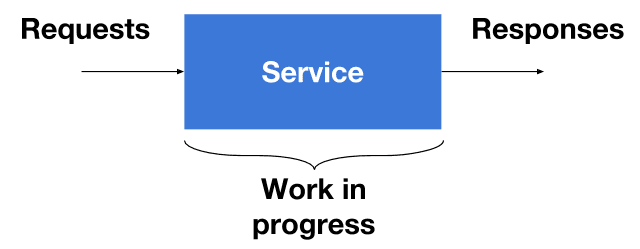
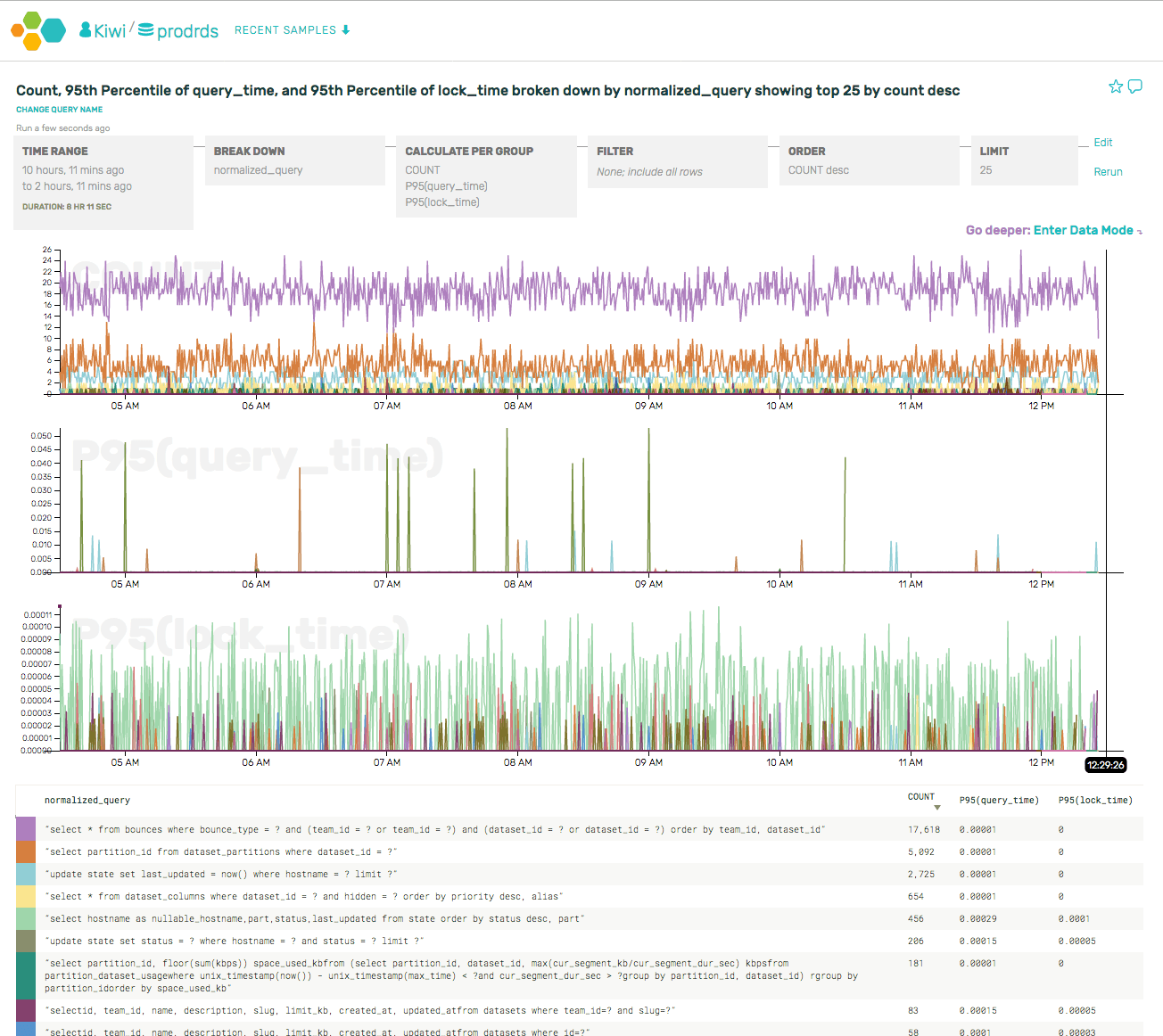
Our storage engine, affectionately known as Retriever, has served us faithfully since the earliest days of Honeycomb. It’s a tool that writes data to disk and reads it back in a way that’s optimized for the time series-based queries our UI and API makes. Its architecture has remained mostly stable through some major shifts in the surrounding system it supports, notably including our 2021 implementation of a new data model for environments and services. As usage of this feature has grown, however, we’ve noticed Retriever creaking in novel ways, pushing us to reconsider a core architectural choice.