Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Reid Savage
One of the things that struck me upon joining Honeycomb was the seemingly laissez-faire approach we took towards internal SLOs. From my own research (beginning with the classic SRE book, following Google’s example), I came to these conclusions: -SLOs are strict. They aren’t as binding as an SLA, but burning through your error budget is bad. -SLOs/SLIs need to be documented somewhere, with a formal specification, and approved by stakeholders. -SLOs should drive customer-level SLAs. -Teams should be mandated to create a minimum number of SLOs for the services they own.
Martin Thwaites
In the last few years, the usage of databases that charge by request, query, or insert—rather than by provisioned compute infrastructure (e.g., CPU, RAM, etc.)—has grown significantly. They’re popular for a lot of the same reasons that serverless compute functions are, as the cost will scale with your usage. No one is using your site? No problem: you’re not charged.
Wren Walker
It may surprise you to hear, but Honeycomb doesn’t currently have a platform team. We have a platform org, and my title is Director of Platform Engineering. We have engineers doing platform work. And, we even have an SRE team and a core services team. But a platform team? Nope. I’ve been thinking about what it might mean to build a platform team up from scratch—a situation some of you may also be in—and it led me to asking crucial questions.
Liz Fong-Jones
Recently, Honeycomb held a roundtable discussion (available on demand) with Camal Cakar, Senior Site Reliability Engineer at Jimdo; Pierre Lacerte, Director of Software Development at Upgrade; and Kristin Smith, DevOps Engineer at Campspot. We talked about using OpenTelemetry and explained some important lessons the panelists learned—and are still learning in some cases. Here are five best practices based on these lessons and Honeycomb’s own experience with OpenTelemetry.
Christine Yen
As long as humans have written software, we’ve needed to understand why our expectations (the logic we thought we wrote) don’t match reality (the logic being executed). To that end, we developed techniques to help measure reality—logging text strings, or capturing aggregated metrics—and persevered, seeking out newer and fancier logging or monitoring solutions over the intervening decades.
Nick Rycar
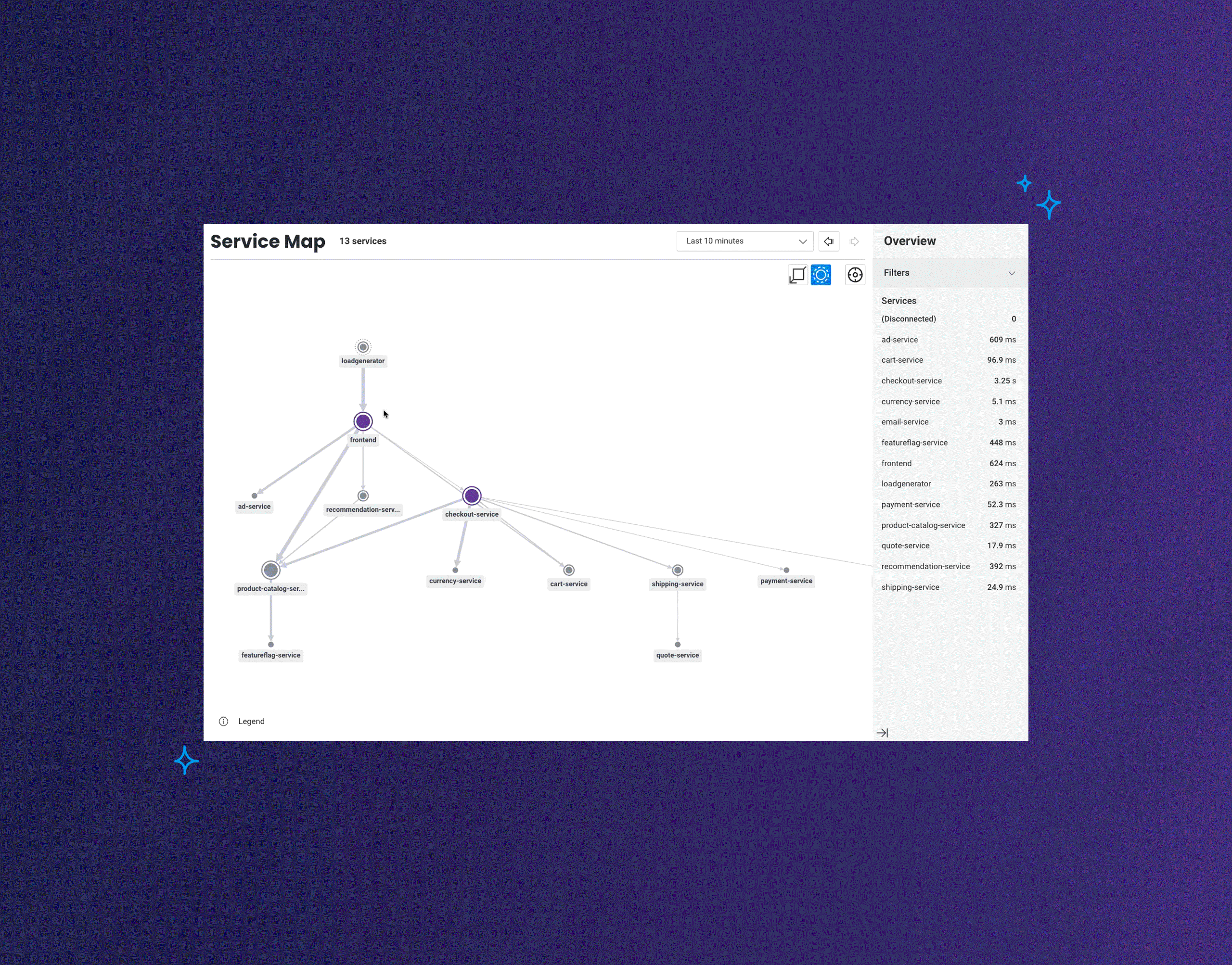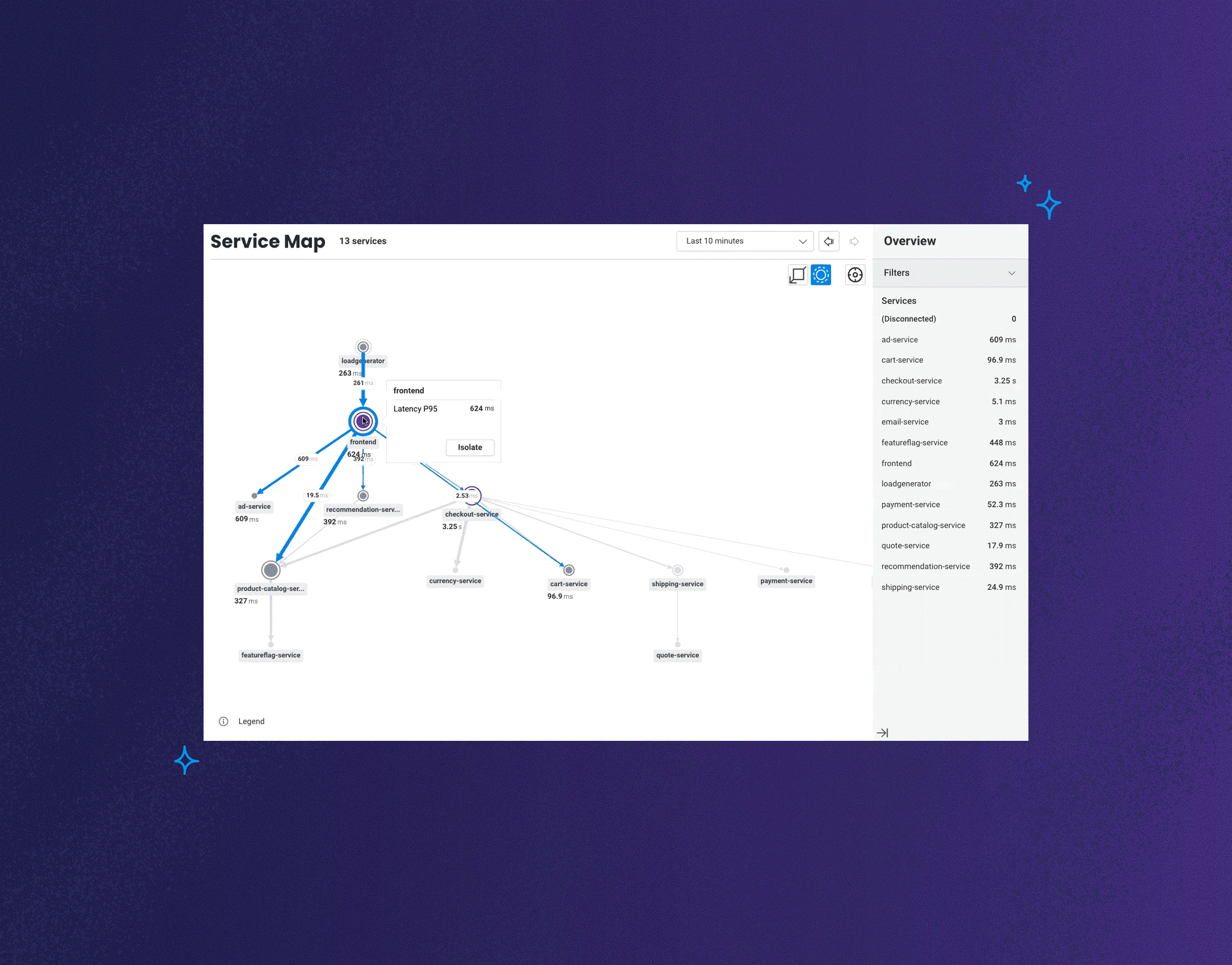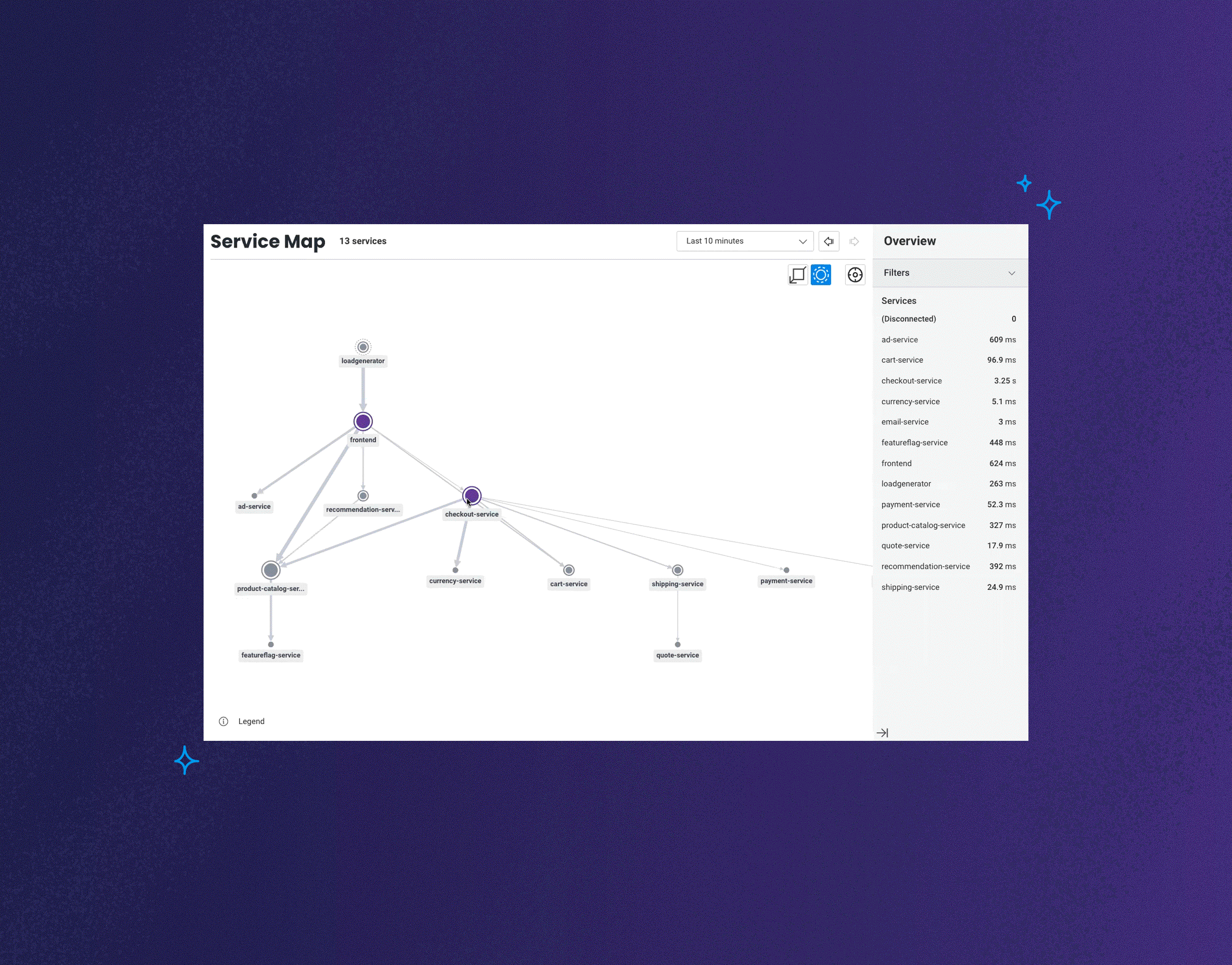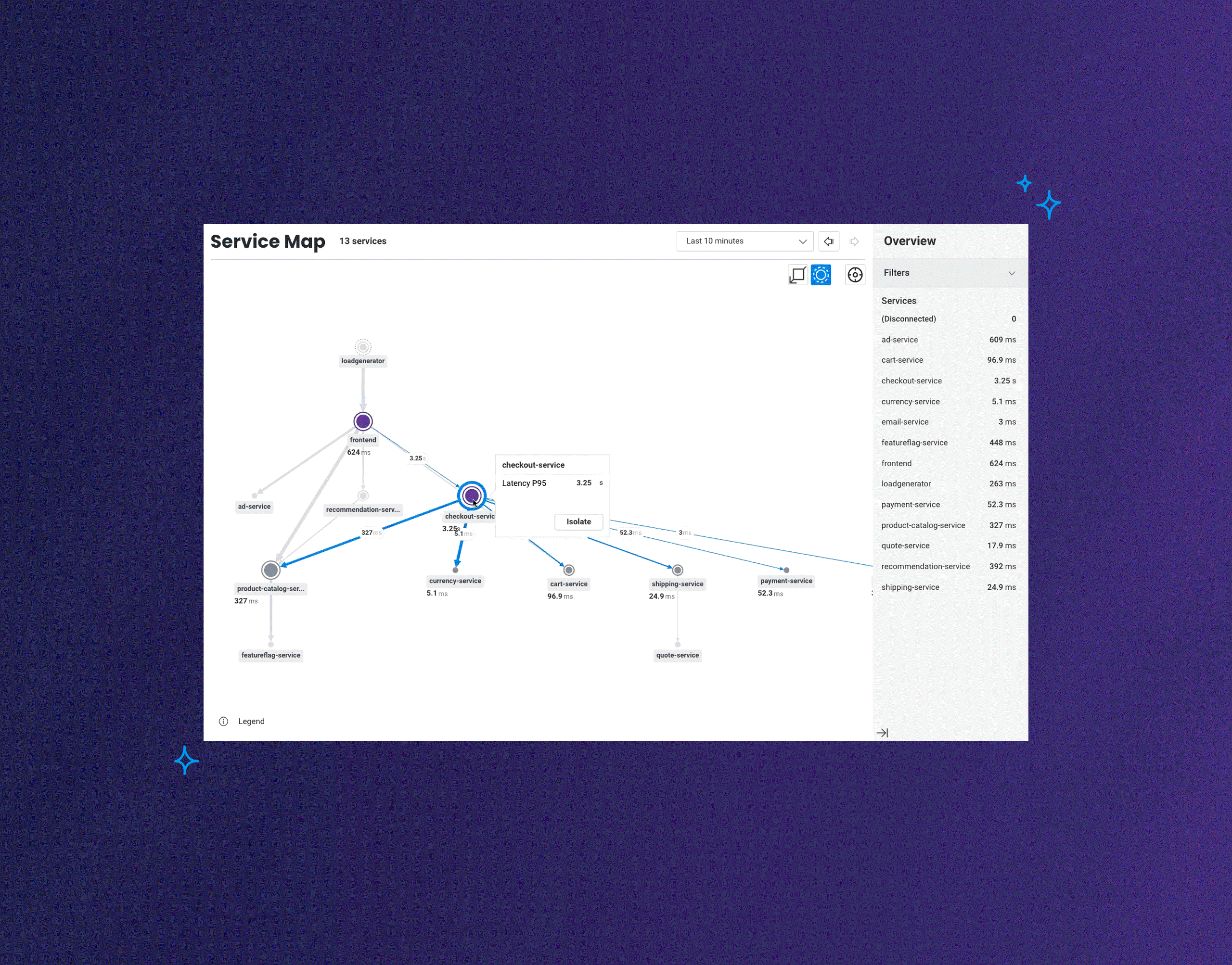
Today, we’re announcing the launch of Honeycomb Service Map. This isn’t your grandparent’s version of a service map. This feature reimagines what it is that you want to know or investigate when looking at visualizations of how your services communicate with one another.
George Miranda
If you build or maintain code in GitHub, the Honeycomb Buildevents Action can help you optimize the performance of your build pipelines in GitHub Actions. This blog introduces you to the gha-buildevents Action and a new hands-on quickstart guide that will show you the inner workings of GitHub Actions workflows, the buildevents tool, and the Honeycomb UI.
Michael Sickles
Getting existing telemetry into Honeycomb just got easier! With the release of the Datadog APM Receiver, you can send your Datadog traces to the OpenTelemetry Collector, and from there, to any OpenTelemetry-compatible endpoint.
Matt Ransford
Network topology can get very complicated in the cloud, especially when you’re sending data to external SaaS providers. You will likely need to configure gateways and firewalls and keep close tabs on those points of egress. However, if your infrastructure exists within AWS, there’s a much simpler way and that’s through an AWS PrivateLink endpoint.
Jessica Kerr (Jessitron)
When you want to direct your observability data in a uniform fashion, you want to run an OpenTelemetry collector. If you have a Kubernetes cluster handy, that’s a useful place to run it. Helm is a quick way to get it running in Kubernetes; it encapsulates all the YAML object definitions that you need. OpenTelemetry publishes a Helm chart for the collector.
Craig Atkinson
Today, I’d like to share with you a new community-contributed integration that helps you optimize and debug your Gradle builds. This new Gradle plugin is available today, is free to use, and you can use it immediately with a free Honeycomb account.
Fred Hebert
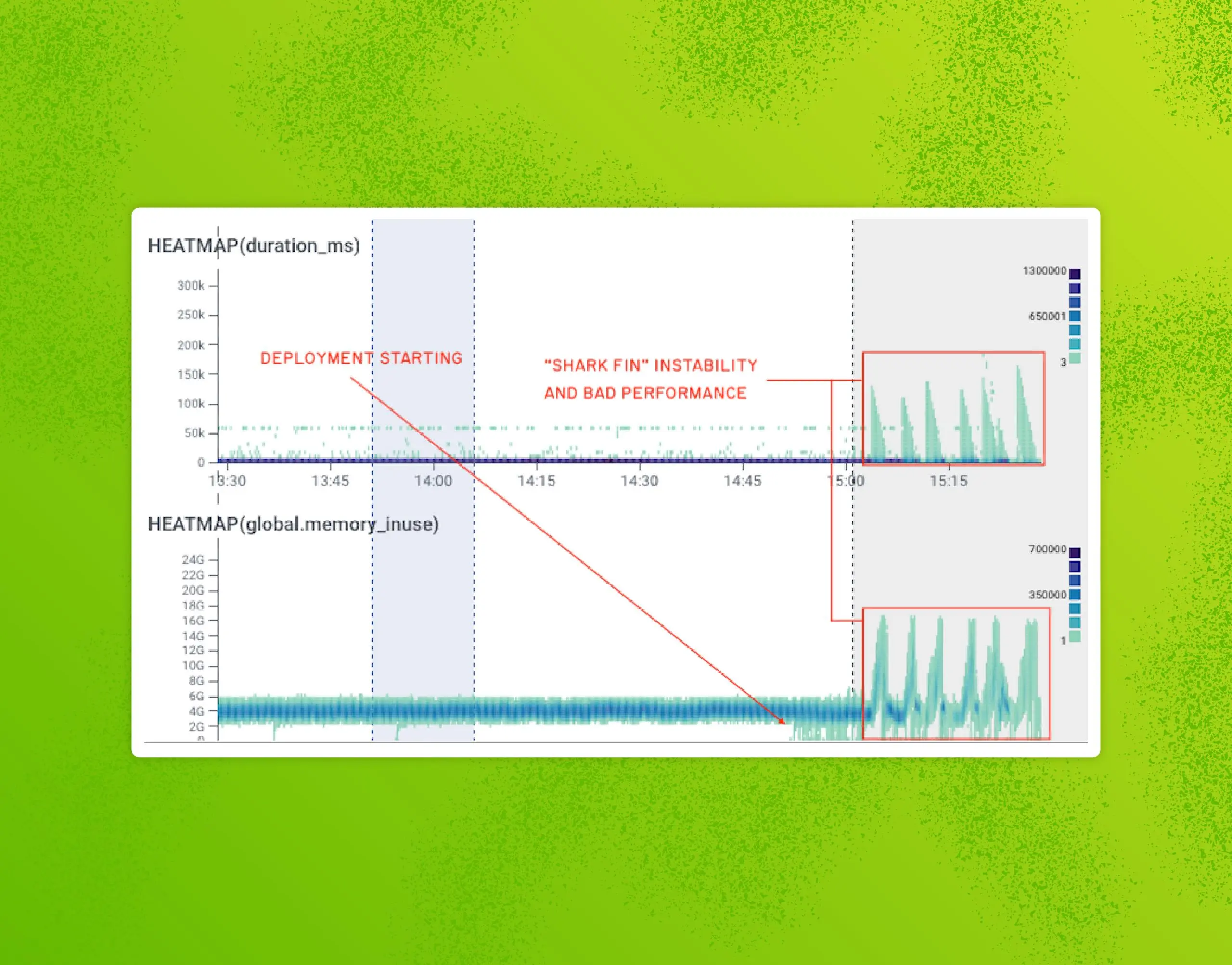
In this incident review, we’ll cover the outage from September 8th, 2022, where our ingest system went down repeatedly and caused interruptions for over eight hours. We will first cover the background behind the incident with a high-level view of the relevant architecture, how we tried to investigate and fix the system, and finally, we’ll go over some meaningful elements that surfaced from our incident review process.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Fahim Zaman
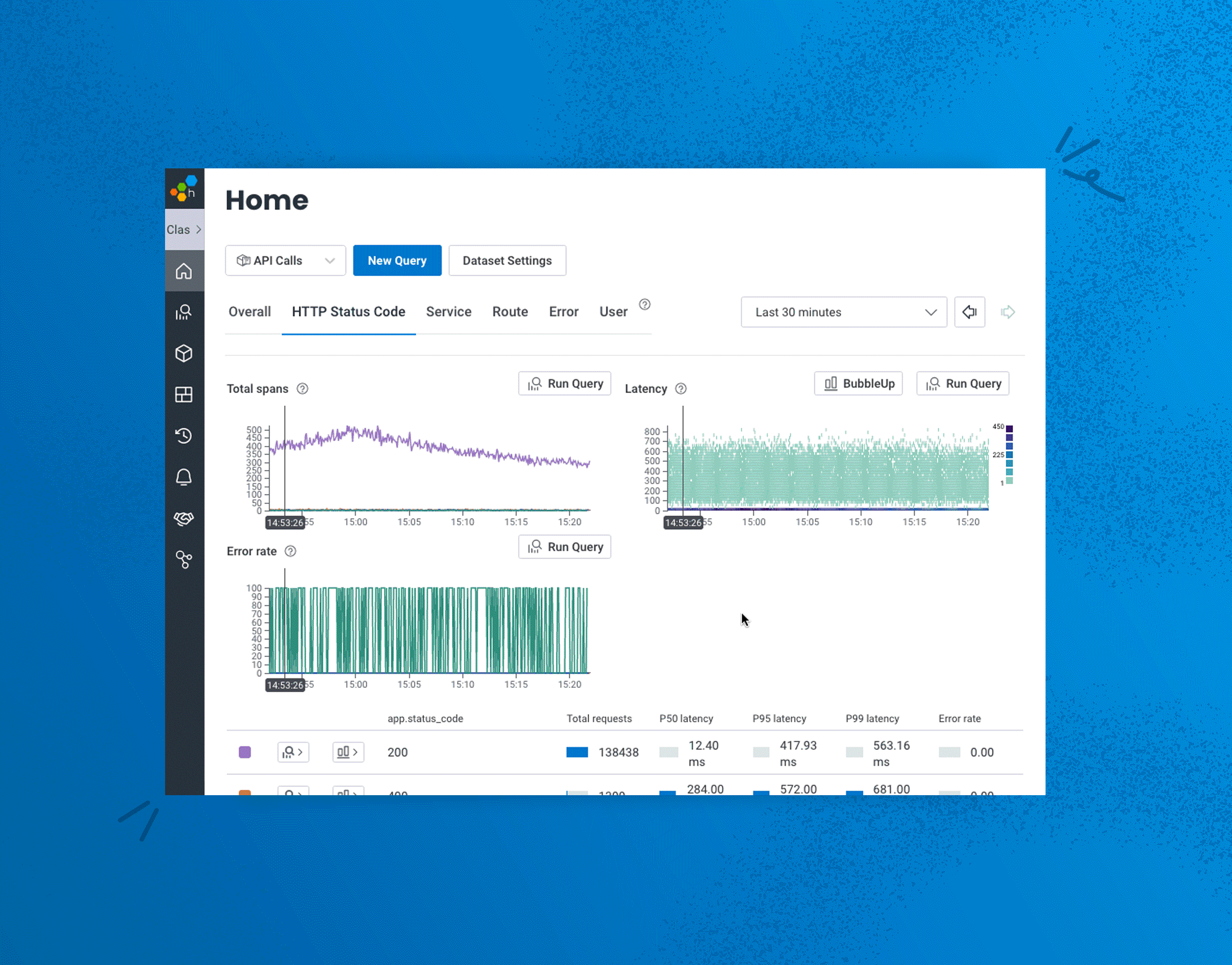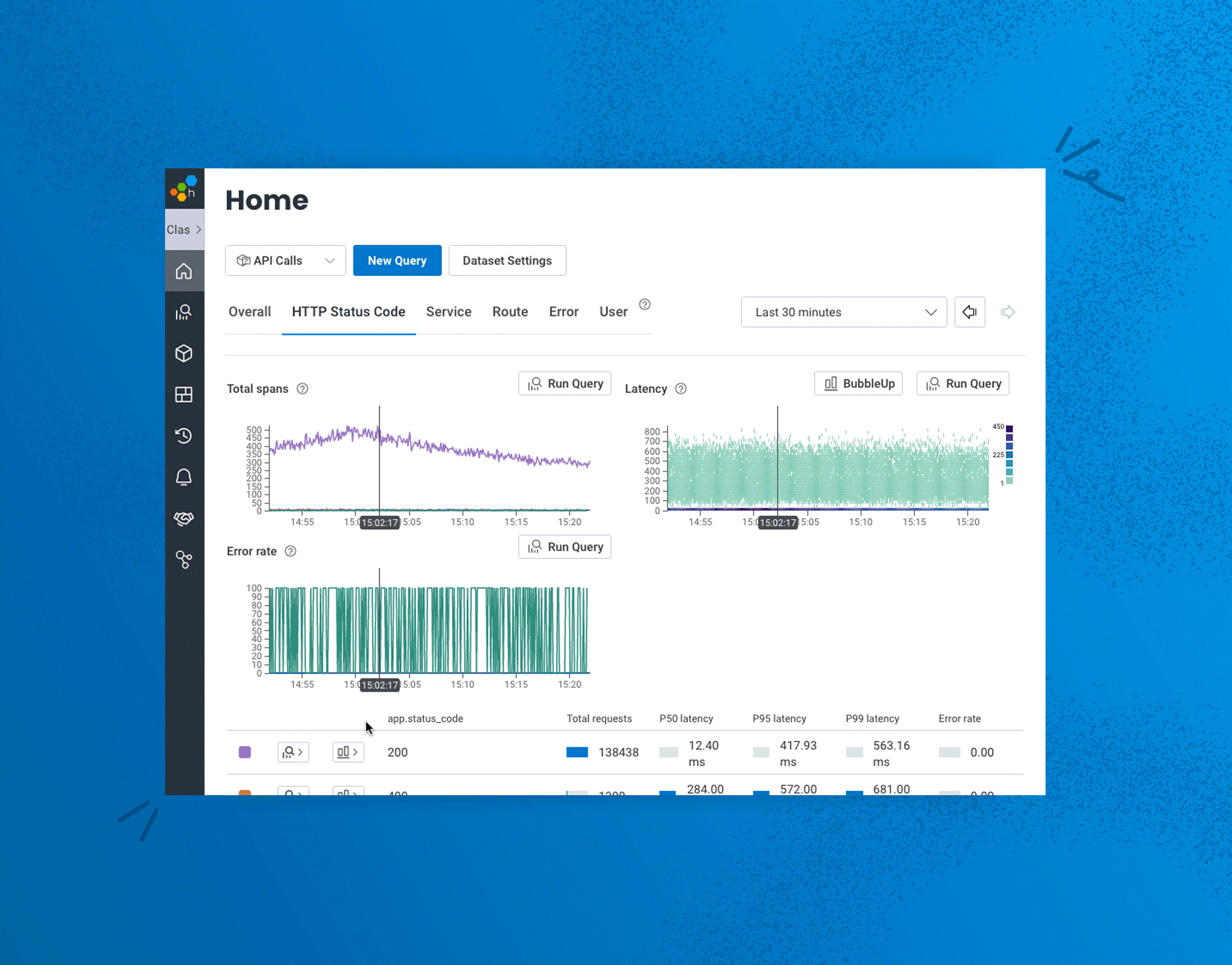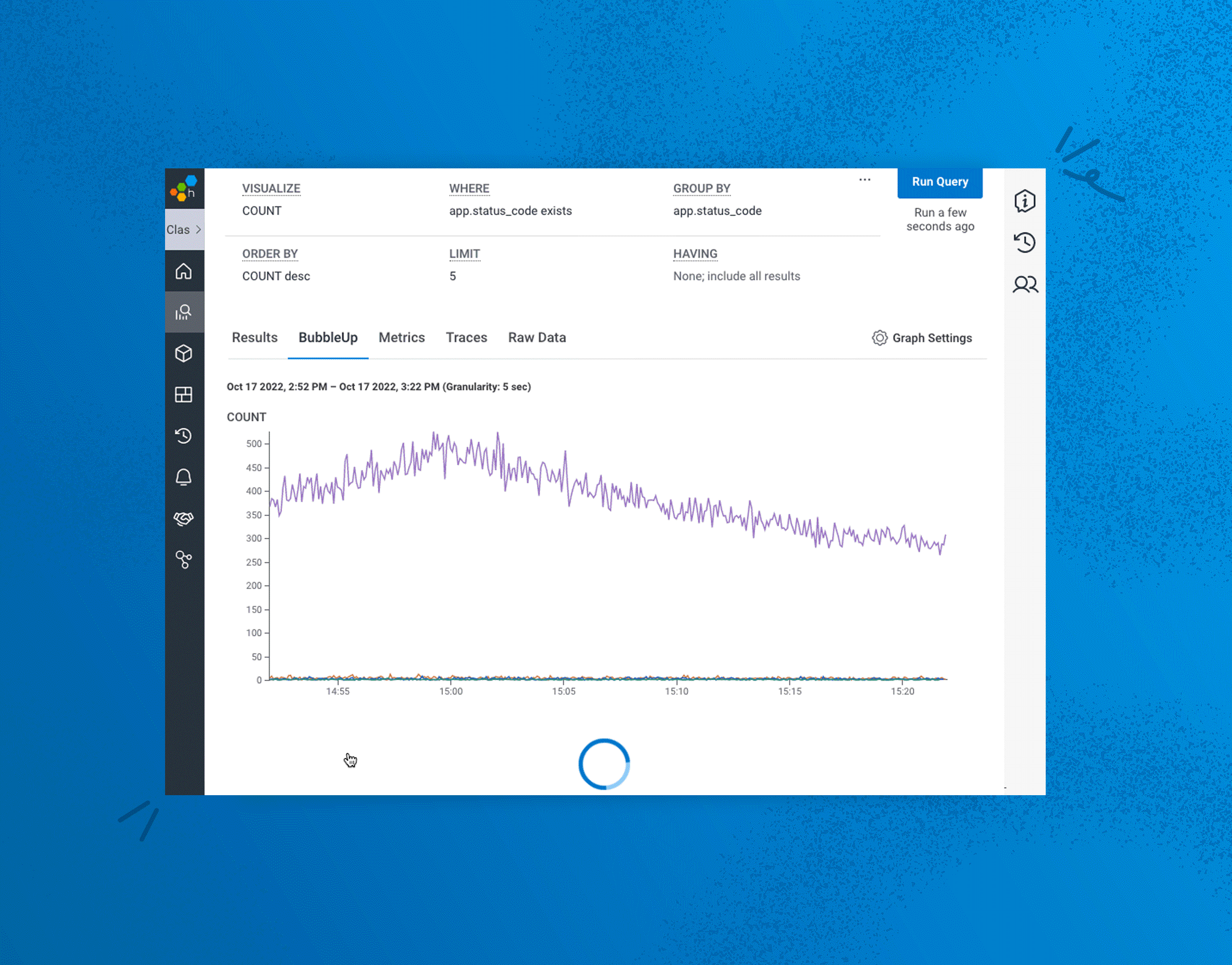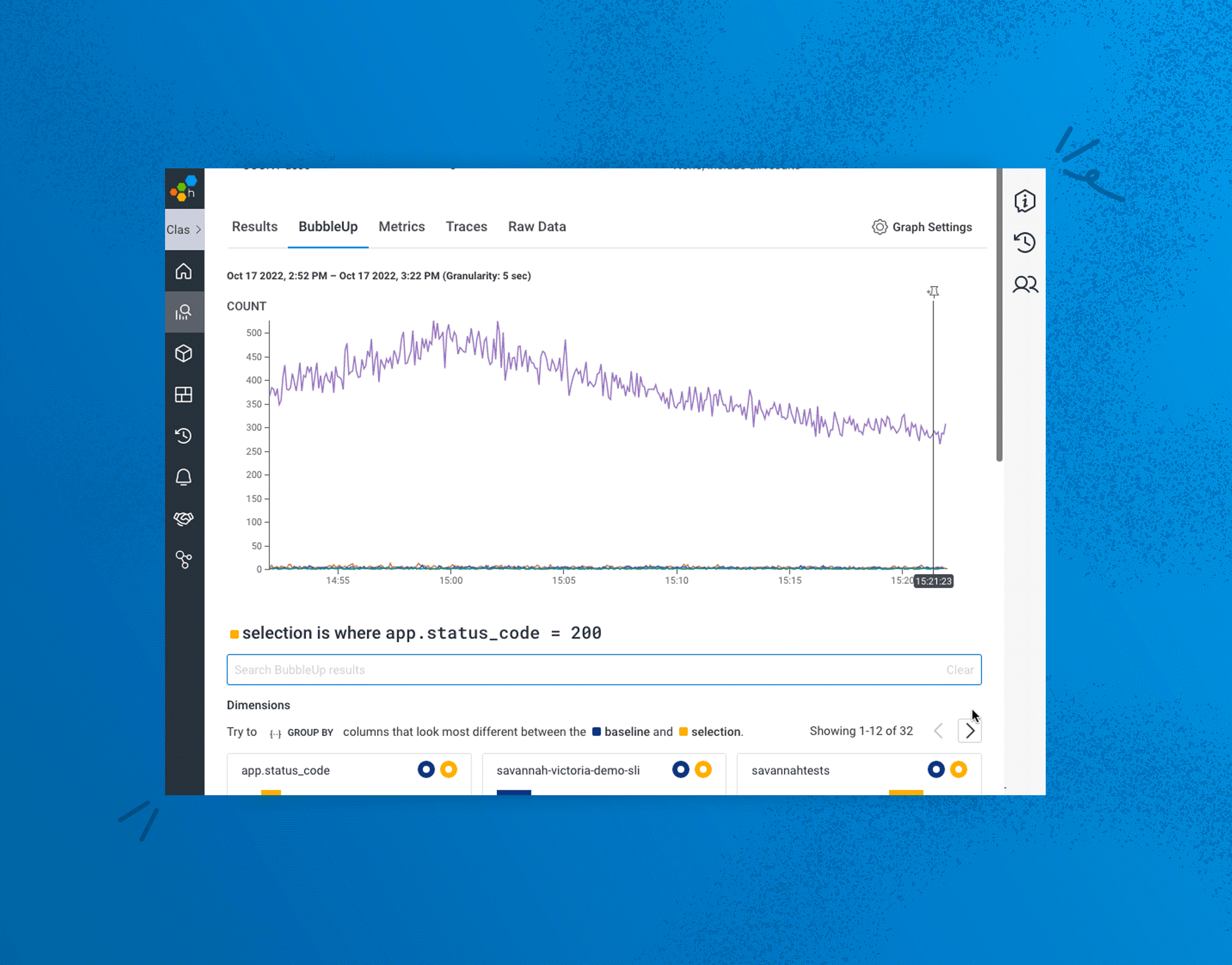
We’re thrilled to share that we’ve made significant enhancements to BubbleUp that will enable users to BubbleUp from more parts of the Honeycomb UI beyond heatmaps. This means users can leverage BubbleUp’s powerful pattern detection on specific groups of users or conditions beyond numeric values, such as users from a particular region, using specific devices or operating systems that are experiencing a particular error message—or are using a unique part of your application, such as a discount code. This ability dramatically accelerates the debugging workflow because you can investigate so many more combinations of factors by asking a wider range of questions about your data to uncover underlying issues in way fewer steps, all from the same UI.
Phillip Carter
Just a few short months ago, we talked about a bunch of updates to Honeycomb’s support for OpenTelemetry. To the surprise of no one, we’ve got more updates to share!
You know that old adage about not seeing the forest for the trees? In our Authors’ Cut series, we’ve been looking at the trees that make up the observability forest—among them, CI/CD pipelines, Service Level Objectives, and the Core Analysis Loop. Today, I’d like to step back and take a look at how observability fits into the broader technical and cultural shifts in technology: cloud-native, DevOps, and SRE.
Charity Majors
I am thrilled to share with you that Honeycomb now has a Field CTO: our very own Liz Fong-Jones.
How do you solve the people and culture problems that are necessary in making the shift to adopt observability practices? And once you instill those changes, how do measure the benefits?
Matt Morris
Today, I’d like to tell you about a new community-contributed integration that connects Honeycomb to your ServiceNow workflows. My new integration reimagines what’s possible when connecting observability tools with ITSM systems. This post explains how it works and how to get started with it.
Feature Focus: September 2022. Here’s a look at improvements we’ve made to Honeycomb in September, including: updates to a buuunch of APIs, new integrations, and Refinery upgrades.
In the beginning, there were people who wrote and ran software. At some point, we spun away ops skills from dev skills into two different professions, but that turned out to be a ginormous mistake, so along came DevOps to reunify them. Nowadays, ops as an independent profession is in the process of fading out. Companies are spinning down their ops teams left and right. Engineers who formerly identified as sysadmins or operations have turned into DevOps engineers, and soon there will just be “software people” again. This is the way of things.