Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Michael Sickles
Large Language Models (LLMs) are all the rage in software development, and for good reason: they provide crucial opportunities to positively enhance our software. At Honeycomb, we saw an opportunity in the form of Query Assistant, a feature that can help engineers ask questions of their systems in plain English. But we certainly encountered issues while building it—issues you’ll most likely face too if you’re building a product with LLMs—with the main one being, how do we get the model to return data in a way that works with our softwa
Austin Parker
Who is software for? It’s an interesting question, because there’s an obvious answer. It’s for the users, right? If your job is to write software, then it’s implied that the most important thing you should care about is the experience people have when they use your software. I think this is a bit of an over-simplification, though. Yes, we build software for our users, but we also build it for ourselves. At some level, I believe all developers are in it for themselves. They like to see the thinking rock respond to the commands they give it. There’s a level of intellectual curiosity that grips many of us when we write software, the quiet joy of getting one over on this unfeeling collection of silicon and cobalt, bending it to our will and mastering its arcane language.
Martin Thwaites
Kubernetes has been around for nearly 10 years now. In the past five years, we’ve seen a drastic increase in adoption by engineering teams of all sizes. The promise of standardization of deployments and scaling across different types of applications, from static websites to full-blown microservice solutions, has fueled this sharp increase.
Savannah Morgan
Understanding production has historically been reserved for software developers and engineers. After all, those folks are the ones building, maintaining, and fixing everything they deliver into production. However, the value of software doesn’t stop the moment it makes it to production. Software systems have users, and there are often teams dedicated to their support.
Phillip Carter
Like many companies, earlier this year we saw an opportunity with LLMs and quickly (but thoughtfully) started building a capability. About a month later, we released Query Assistant to all customers as an experimental feature. We then iterated on it, using data from production to inform a multitude of additional enhancements, and ultimately took Query Assistant out of experimentation and turned it into a core product offering. However, getting Query Assistant from concept to feature diverted R&D and marketing resources, forcing the question: did investing in LLMs do what we wanted it to do?
Emil Protalinski
Do you want to build software faster and release it more often without the risks of negatively impacting your user experience? Imagine a world where there is not only less fear around testing and releasing in production, but one where it becomes routine. That is the world of feature flags.
Mike Terhar
Containers are an amazing technology. They provide huge benefits and create useful constraints for distributing software. Golang-based software doesn’t need a container in the same way Ruby or Python would bundle the runtime and dependencies. For a statically compiled Go application, the container doesn’t need much beyond the binary. Since the software is intended to run in a Kubernetes cluster, the container provides the release and distribution mechanism which the Helm chart uses to refer to these binaries. It also allows releasing multiple processor architectures to reference their own images. For general troubleshooting, some pretty good resources exist, like Refinery and the OpenTelemetry Collector.
Charity Majors
Many software engineers are encountering LLMs for the very first time, while many ML engineers are being exposed directly to production systems for the very first time. Both types of engineers are finding themselves plunged into a disorienting new world—one where a particular flavor of production problem they may have encountered occasionally in their careers is now front and center.
Jessica Kerr (Jessitron)
In high school chemistry and then college physics labs, we learned a strong definition of “experiment.” Experiments are tied to the Scientific Method, responsible for advancement of human knowledge.
Mei Luo
Whether you’re a new Honeycomb user or a seasoned expert looking to uncover fresh insights, chances are you’ve sent tremendous amounts of data into Honeycomb already. The question is: now what? We have the answer: Board templates.
Ian Duncan
At work, we use OpenTelemetry extensively to trace execution of our Haskell codebase. We struggled for several months with a mysterious tracing issue in our production environment wherein unrelated web requests were being linked together in the same trace, but we could never see the root trace span.
The OpenTelemetry Collector is a useful application to have in your stack. However, deploying it has always felt a little time consuming: working out how to host the config, building the deployments, etc. The good news is the OpenTelemetry team also produces Helm charts for the Collector, and I’ve started leveraging them. There are a few things to think about when using them though, so I thought I’d go through them here.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Fred Hebert
On July 25th, 2023, we experienced a total Honeycomb outage. It impacted all user-facing components from 1:40 p.m. UTC to 2:48 p.m. UTC, during which no data could be processed or accessed. This outage is the most severe we’ve had since we had paying customers. In this review, we will cover the incident itself, and then we’ll zoom back out for an analysis of multiple contributing elements, our response, and the aftermath.
Max Aguirre
What do mall food courts and Honeycomb have in common? We both love sampling! Not only do we recommend it to many of our customers, we do it ourselves. But once Refinery (our tail-based sampling proxy) is set up, what comes next?
Adnan Rahić
Our friends at Tracetest recently released an integration with Honeycomb that allows you to build end-to-end and integration tests, powered by your existing distributed traces. You only need to point Tracetest to your existing trace data source—in this case, Honeycomb. This guest blog post from Adnan Rahić walks you through how the integration works.
The Accelerate State of Devops Report highlights four key metrics (known as the DORA metrics, for DevOps Research & Assessment) that distinguish high-performing software organizations: deployment frequency, lead time for changes, time-to-restore1, and change…
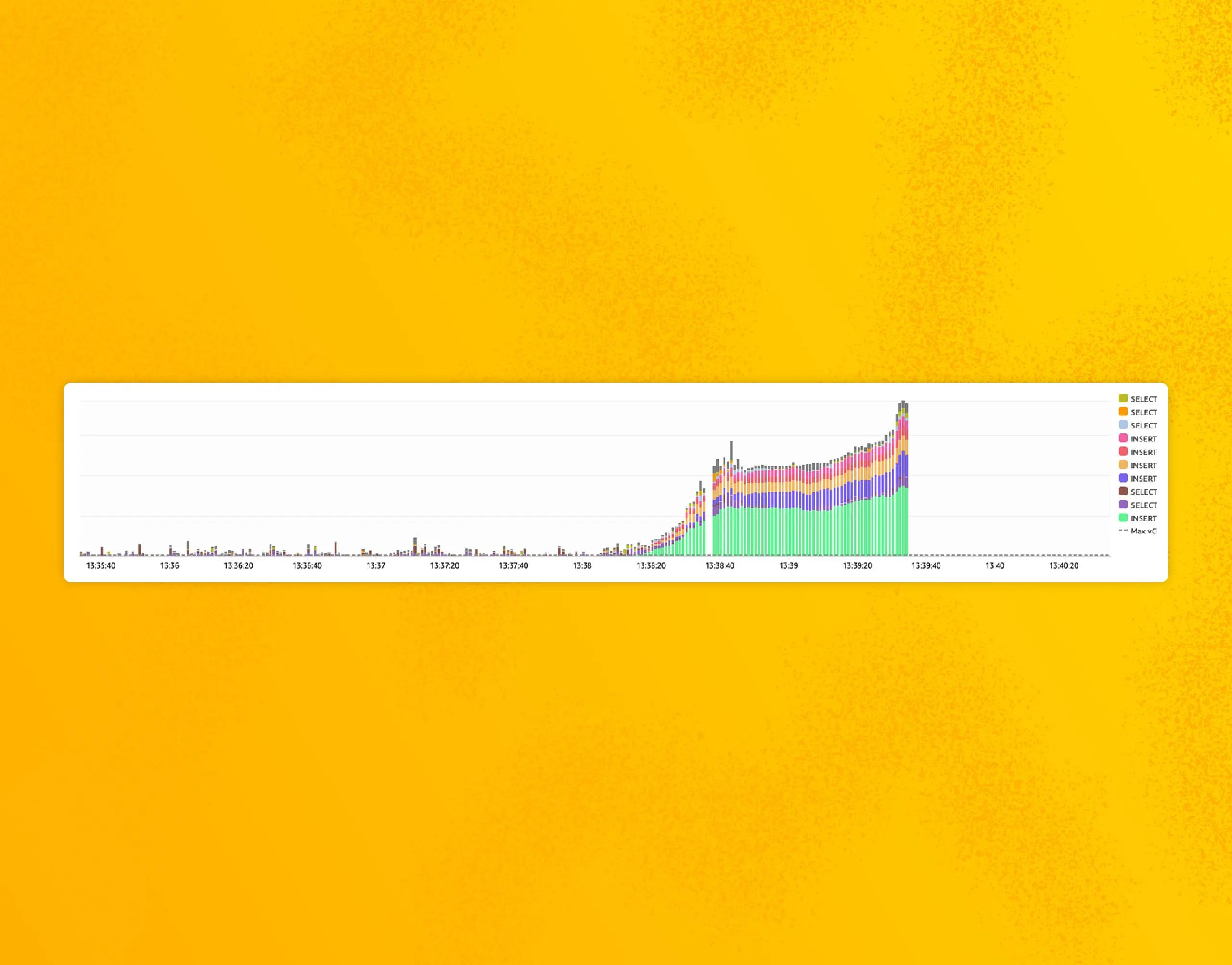
Honeycomb is massively powerful at delivering detailed answers from the last several weeks of system telemetry within seconds. It keeps you in the flow state needed to work through complex system failures while asking question after question to get closer to the answer. The biggest trade-off is the 60 day retention limit.
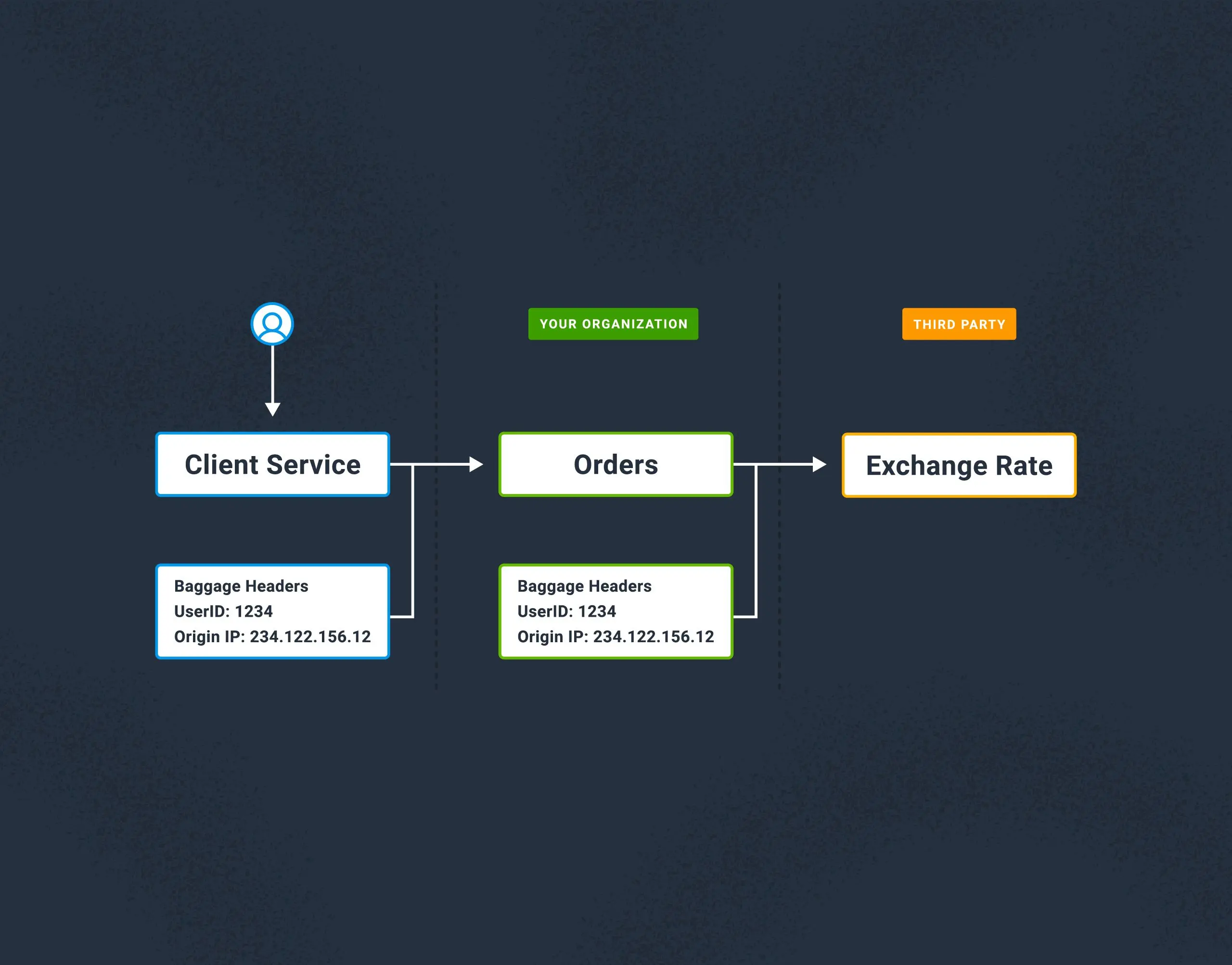
One of the issues with the W3C trace context is that it doesn’t define any standards for how far a trace is to propagate. If a third party accidentally sends trace headers from their service, you’ll use their trace IDs and baggage data. This can have unwanted affects on your telemetry backend, such as the trace showing missing root spans, or including multiple API calls in a single trace at the top level. This makes understanding and debugging trace data hard. Worse though, the baggage data from the third party could contain PII data, which would therefore mean you’re processing PII without realizing it.
Emily Nakashima
Engineers often feel they aren’t allowed enough time to address tech debt. Product partners wonder why engineers spend so much time working on it—or at least talking about it. “The business” always seems to insinuate that engineers should do less of it, instead focusing on shipping value to customers. And despite all this, many engineering leaders worry their teams may actually be under-investing in tech debt, in ways that could negatively impact the business over the long term.
The OpenTelemetry Go project now supports automatic instrumentation via eBPF! This is a big milestone for the project and makes it significantly easier to generate data from your Go apps.