Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Fahim Zaman
For developers, understanding the performance of shipped code is crucial. Through the last decade, a tablestake function in software monitoring and observability solutions has been to save and track app metrics. Engineers love tools that get out of your way and just work, and the appeal of today’s best-in-class application performance monitoring (APM) suites lies in a seamless day zero experience with drop-in agent installs, button click integrations, and immediate metrics collection. However, the success of no-hassle metrics comes with a caveat—the internet is replete with examples of premiere application monitoring costs spiraling beyond expectations.
Winston Hearn
I’ve been thinking about a risk that—if I’m not careful—could severely hinder my team’s ability to ship on time, celebrate success, and continue work after launch: burnout. I don’t see burnout mentioned often when the work of product management is discussed, but I believe it should be taken much more seriously.
Jessica Kerr (Jessitron)
In a keynote at AI.Dev, Robert Nishihara (CEO, Anyscale) described the shift: A year ago, the people working with ML models were ML experts. Now, they’re developers. A year ago, the process was to experiment with building a model, then put a product on top of it. Now, it’s ship a product, find the market fit, then create customized models.
Natalie Friedman
Today marks an exciting milestone at Honeycomb, and we’re thrilled to share it with you. We officially launched our integration with Microsoft Teams, a step forward in our continuous effort to streamline and enhance your observability experience. Teams now joins our growing list of over 100 Honeycomb integrations.
Phillip Carter
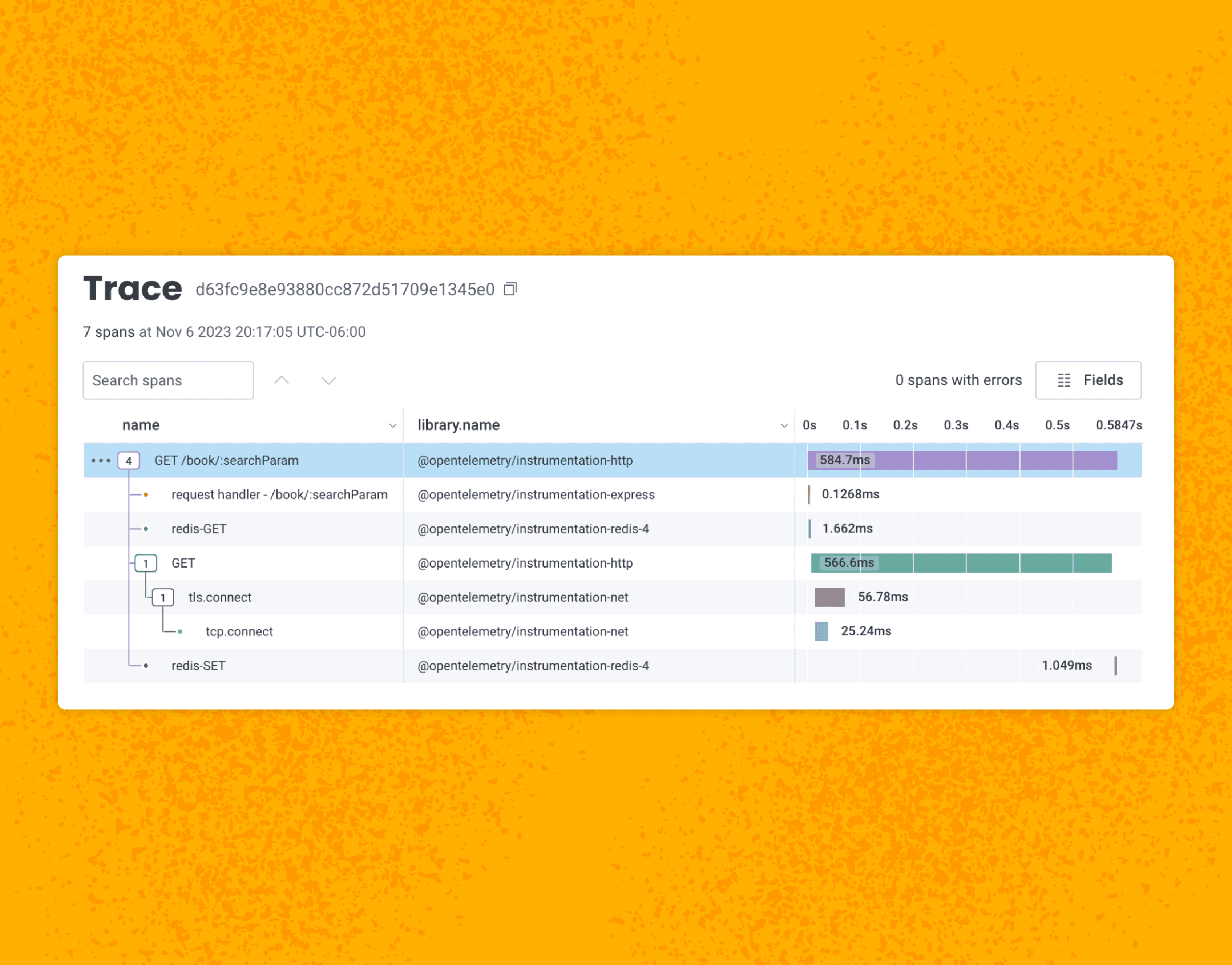
Earlier this year, the folks working on OpenTelemetry launched an effort to stabilize HTTP Semantic Conventions. In November 2023, OpenTelemetry announced that HTTP Semantic Conventions were stable. They accomplished this by merging the existing HTTP Semantic Conventions with the Elastic Common Schema HTTP attribute conventions.
Austin Parker
Cloud-native developers and practitioners gathered from around the world to learn, collaborate, and network at KubeCon/CloudNativeCon North America 2023 between November 6th and 9th at McCormick Place in Chicago, IL—myself included. This wasn’t my first time attending—I’ve been coming to KubeCon since 2016—but it was easily one of the most exciting experiences I’ve had as part of the cloud-native community.
Jamie Danielson
Now that we’ve had time to decompress from Kubecon, we wanted to do a writeup about our collective experience. Six of us spoke at the conference and Charity participated in a panel, so we included short talk recaps.
Purvi Kanal
So you’ve taken a look at the core web vitals for your site and… it’s not looking good. You’re overwhelmed, and you don’t know what change to make because everything seems like too big of a project to make a real difference. There are so many measurements to keep track of and the standards cited seem even scarier. This is extremely normal. Web performance standards can feel impossible to meet for a lot of us.
Observability is important to understand what’s happening in production. But carving out the time to add instrumentation to a codebase is daunting, and often treated as a separate task to writing features. This means that we end up instrumenting for observability long after a feature has shipped, usually when there’s a problem with it and we’ve lost all context. What if we instead treated observability similarly to how we treat tests? We don’t submit code without a test, so let’s do the same with observability: treat it as part of the feature while the code is still fresh in our mind, with the benefit of being able to observe how the feature behaves in production.
George Miranda
Ever since we launched Query Assistant last June, we’ve learned a lot about working with—and improving—Large Language Models (LLMs) in production with Honeycomb. Today, we’re sharing those techniques so that you can use them to achieve better outputs from your own LLM applications. The techniques in this blog are a new Honeycomb use case. You can use them today. For free. With Honeycomb. If you’re running LLM apps in production (or thinking about it), these approaches should be useful.
Mike Terhar
A lot of reasoning in content is predicated on the audience being in a modern, psychologically safe, agile sort of environment. It’s aspirational, so folks who aren’t in those environments may feel like the path there includes doing “the new thing” or using “the new tool.” If you write software and your employer hasn’t caught up to all the newest, best ways to work, I hope this pragmatic post helps you sleep better at night.
Fred Hebert
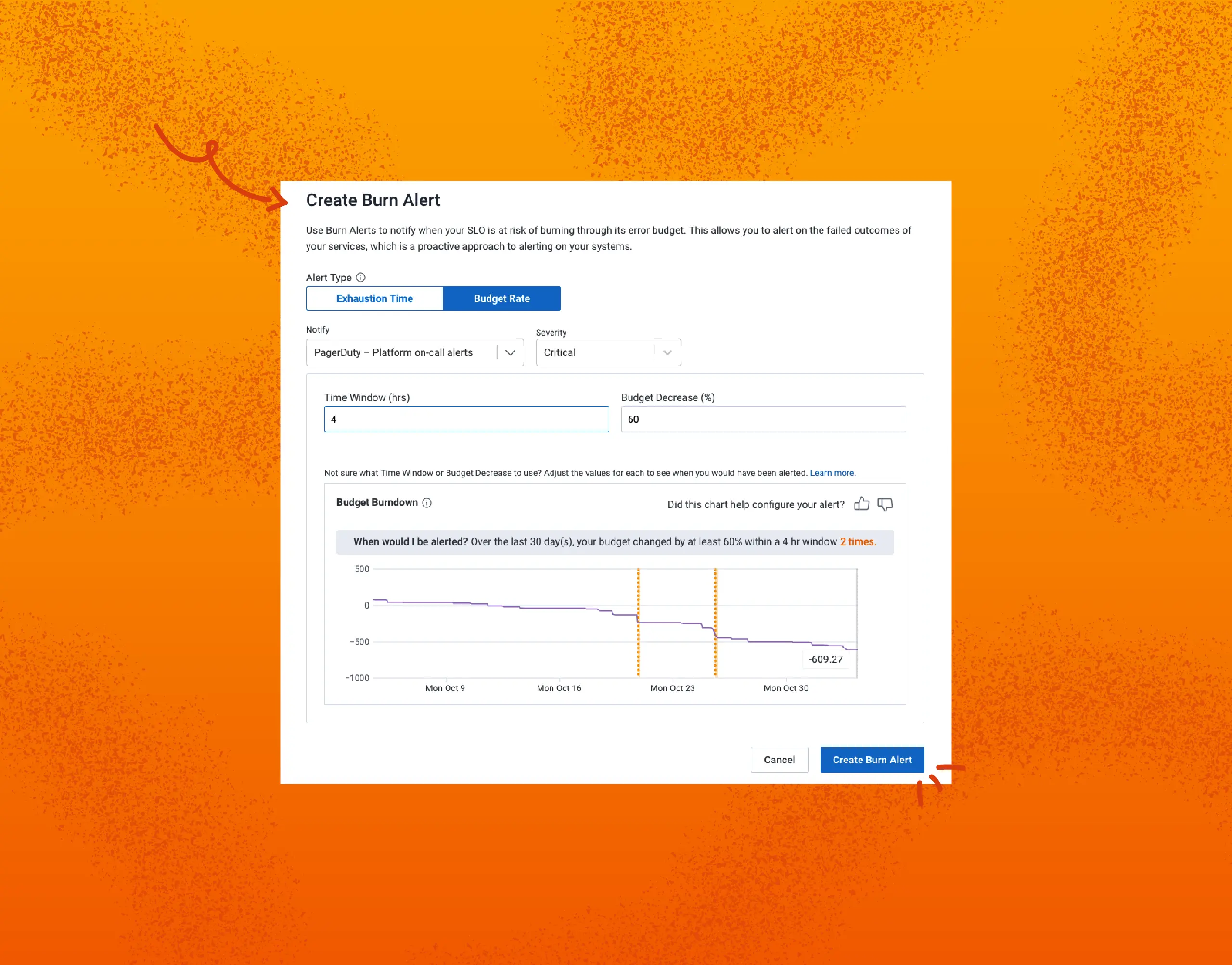
As someone living the Honeycomb ops life for a while, SLOs have been the bread and butter of our most critical and useful alerting. However, they had severe, long-standing limitations. In this post, I will describe these limitations, and how our brand new feature, budget rate alerts, addresses them.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Stop me if you’ve heard this one before: you just pushed and deployed your latest change to production, and it’s rolling out to your Kubernetes cluster. You sip your coffee as you wrap up some documentation when a ping in the ops channel catches your eye—a sales engineer is complaining that the demo environment is slow. Probably nothing to worry about, not like your changes had anything to do with that… but, minutes later, more alerts start to fire off.
In telemetry jargon, a pipeline is a directed acyclic graph (DAG) of nodes that carry emitted signals from an application to a backend. In an OpenTelemetry Collector, a pipeline is a set of receivers that collect signals, runs them through processors, and then emits them through configured exporters. This blog post hopes to simplify both types of pipelines by using an OpenTelemetry extension called the Headers Setter.
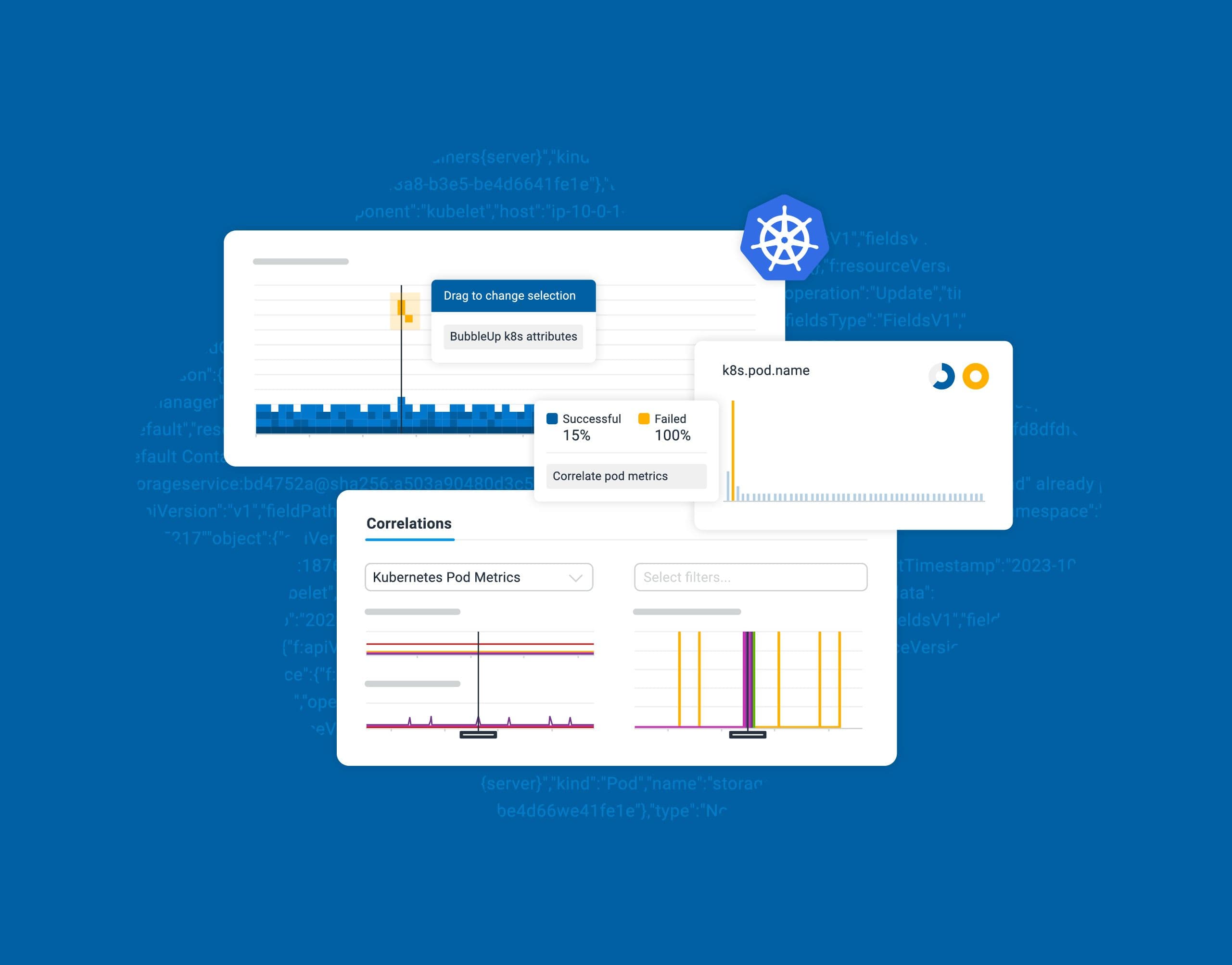
In our continuous journey to support teams grappling with the complexities of Kubernetes environments, we’re thrilled to announce the launch of Honeycomb for Kubernetes, a dedicated solution designed to bridge the growing divide between infrastructure/platform teams and application developers. This is available to all plans (including Free!) at no additional cost.
Martin Thwaites
You probably know that we have a generous free plan that allows you to send 20 million events per month. This is enough for many of our customers. In fact, some have developed neat techniques to keep themselves underneath the event limit. I’m going to share one way here—hopefully no one at Honeycomb notices!
Michael Sickles
Large Language Models (LLMs) are all the rage in software development, and for good reason: they provide crucial opportunities to positively enhance our software. At Honeycomb, we saw an opportunity in the form of Query Assistant, a feature that can help engineers ask questions of their systems in plain English. But we certainly encountered issues while building it—issues you’ll most likely face too if you’re building a product with LLMs—with the main one being, how do we get the model to return data in a way that works with our softwa
Who is software for? It’s an interesting question, because there’s an obvious answer. It’s for the users, right? If your job is to write software, then it’s implied that the most important thing you should care about is the experience people have when they use your software. I think this is a bit of an over-simplification, though. Yes, we build software for our users, but we also build it for ourselves. At some level, I believe all developers are in it for themselves. They like to see the thinking rock respond to the commands they give it. There’s a level of intellectual curiosity that grips many of us when we write software, the quiet joy of getting one over on this unfeeling collection of silicon and cobalt, bending it to our will and mastering its arcane language.
Kubernetes has been around for nearly 10 years now. In the past five years, we’ve seen a drastic increase in adoption by engineering teams of all sizes. The promise of standardization of deployments and scaling across different types of applications, from static websites to full-blown microservice solutions, has fueled this sharp increase.
Savannah Morgan
Understanding production has historically been reserved for software developers and engineers. After all, those folks are the ones building, maintaining, and fixing everything they deliver into production. However, the value of software doesn’t stop the moment it makes it to production. Software systems have users, and there are often teams dedicated to their support.