Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Martin Thwaites
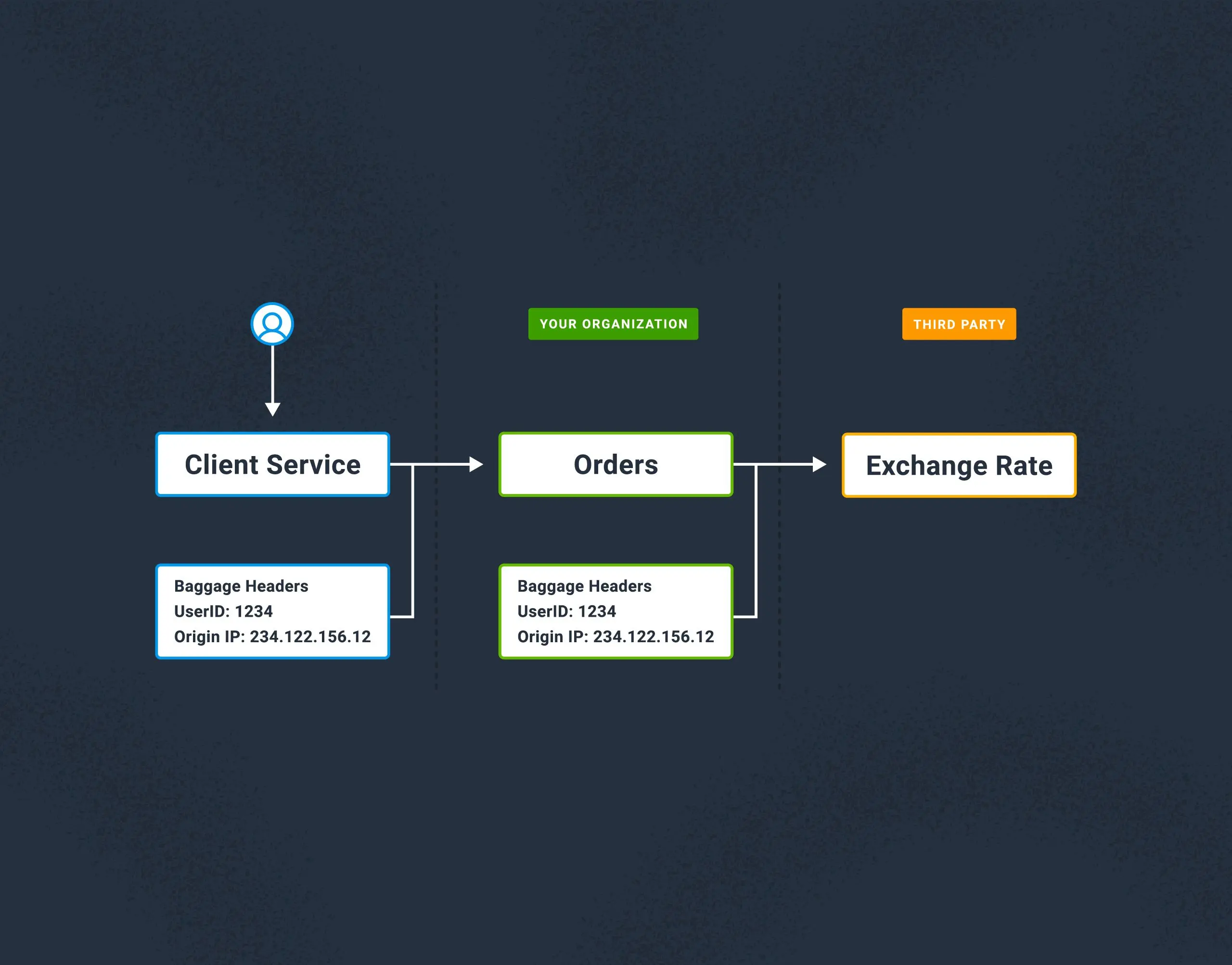
One of the issues with the W3C trace context is that it doesn’t define any standards for how far a trace is to propagate. If a third party accidentally sends trace headers from their service, you’ll use their trace IDs and baggage data. This can have unwanted affects on your telemetry backend, such as the trace showing missing root spans, or including multiple API calls in a single trace at the top level. This makes understanding and debugging trace data hard. Worse though, the baggage data from the third party could contain PII data, which would therefore mean you’re processing PII without realizing it.
Emily Nakashima
Engineers often feel they aren’t allowed enough time to address tech debt. Product partners wonder why engineers spend so much time working on it—or at least talking about it. “The business” always seems to insinuate that engineers should do less of it, instead focusing on shipping value to customers. And despite all this, many engineering leaders worry their teams may actually be under-investing in tech debt, in ways that could negatively impact the business over the long term.
Phillip Carter
The OpenTelemetry Go project now supports automatic instrumentation via eBPF! This is a big milestone for the project and makes it significantly easier to generate data from your Go apps.
Kent Quirk
It’s rare to have too much telemetry—it’s not often that someone says “I wish I didn’t have all this information!” However, telemetry is data, and data is not necessarily information—particularly when you’re drowning in it. Honeycomb’s query engine is so fast and powerful that many customers can send us all their telemetry. As we say on our stickers, “The Backend Can Handle It.”
Valerie Silverthorne
Incident management is the way an organization reacts to any kind of outage (security, broken code, severe weather, or anything that’s disruptive to customer service). Incidents are inherently fraught, not just because they’re time consuming and costly, but because they can potentially poison the well with customers, investors, and even partners.
Nick Travaglini
In this post, we’re going to lay out the guiding principle that unifies the diverse world of CS as we see it—and show how we put it into practice.
Charity once said an off-hand sentence that became a mantra for my transition into the VP of Engineering role: “Directors run the company.” This was said in the context of thinking about how the various management roles around the company interact: line managers run teams and projects, directors run the day-to-day work of the company, and execs (including VPs) focus above all on strategy, external-facing matters, and longer-term planning for the company’s future.
Purvi Kanal
Each CWV measures a specific part of the end user experience. CWV scores can help identify gaps in web page performance. Additionally, Google uses CWV scores as one of the measures it uses to rank pages, which means they are important for SEO.
In February of 2020, I was promoted from Director of Engineering to Honeycomb’s first VP of Engineering. Although Charity wrote an extremely generous public announcement, I hesitated to talk about this new role for quite a while as I was figuring out the job. But since 2020, I’ve noticed how little candid writing there is about paths to the VPE role or what the job is really like.*
Charity Majors
When the Gartner Magic Quadrant Report came out in 2022, we did the professional equivalent of a spit take, then cheered wildly. NOT ONLY did they include observability for the first time ever in their newly revamped 2022 Magic Quadrant for APM & [now] Observability, but they also put us in the Leader Quadrant—our debut appearance!
Mike Terhar
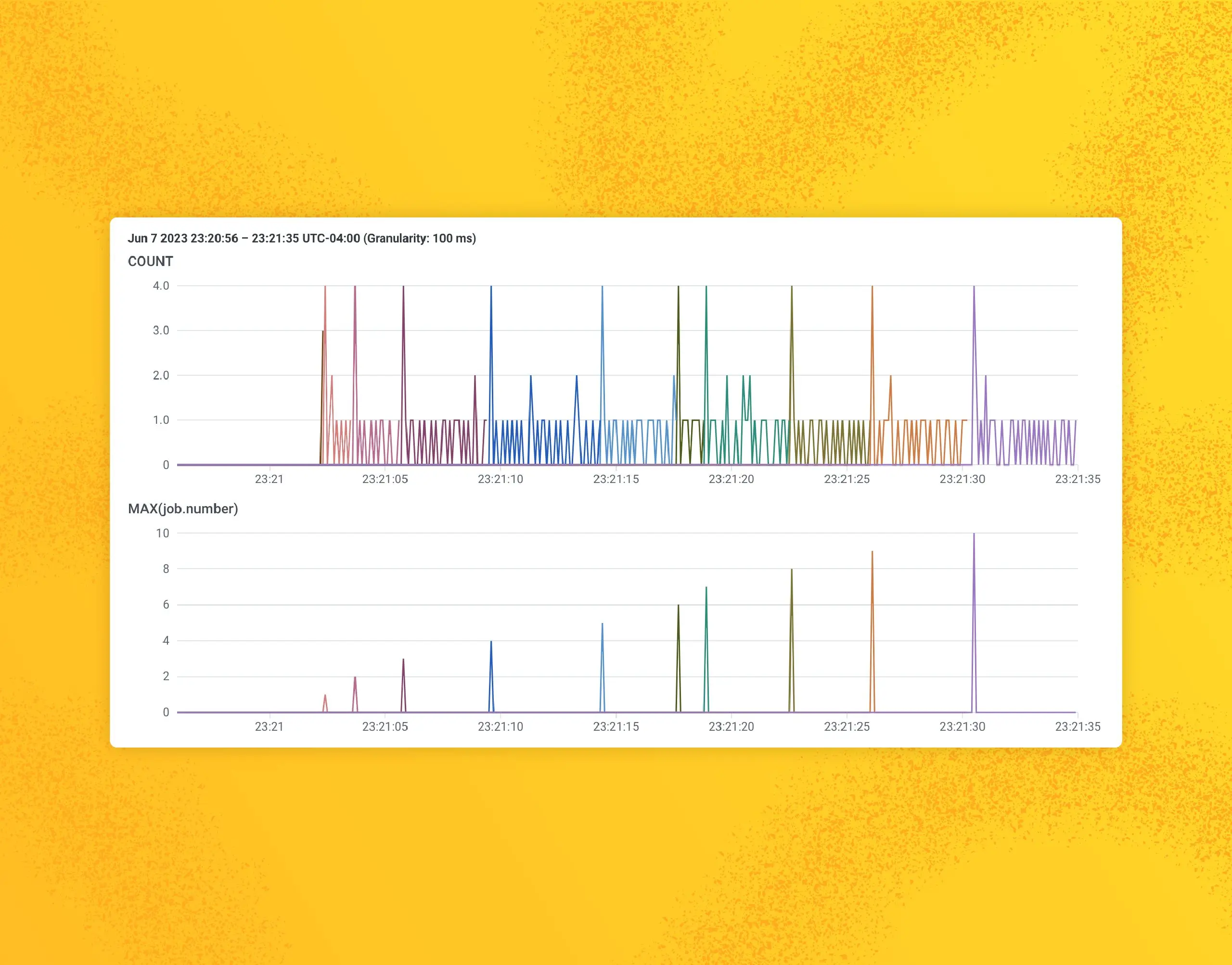
Honeycomb has the ability to receive events from application. These events can take the shape of Honeycomb wide events, OpenTelemetry trace spans, and OpenTelemetry metrics. Because Honeycomb’s backend is very flexible, these OpenTelemetry signals fit in just fine—but sometimes, they have a few quirks. Let’s dive into using metrics the Honeycomb way and cover a few optimizations.
Roel Vista
n technical support, ensuring customer satisfaction and quickly resolving issues are of utmost importance. At Honeycomb, we embrace a comprehensive approach by using our own platform—not only for engineering purposes, but to also empower our support team.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Kyle Moonwright
Insightful proof-of-concepts with a tool can be difficult to undertake due to the demands on valuable resources: time, energy, and people. With a task as grand as observability, how could one truly test if Honeycomb and OpenTelemetry are right for their organization and meet their requirements? For this thought experiment, here’s a comprehensive description of the ideal product evaluation over the course of four weeks, given unlimited resources.
Fred Hebert
People seem to struggle with the idea that there are no repeat incidents. It is very easy and natural to see two distinct outages, with nearly identical failure modes, impacting the same components, and with no significant action items as repeat incidents. However, when we look at the responses and their variations, we can find key distinctions that shows the incidents as related, but not identical.
OpenTelemetry and Beelines were designed with assumptions about the types of traffic that most users would trace. Based on these assumptions, web application and API calls fit very nicely into a trace waterfall view. This is also the set of assumptions for Refinery, our sampling proxy, to manage the traces it processes. These assumptions are true for most traffic.
Jessica Kerr (Jessitron)
At Honeycomb, we are all about observability. In the past, we have proposed observability-driven development as a way to maximize your observability and supercharge your development process. But I have a problem with the terminology, and it is: I don’t want observability to drive your development.
In early May, we released the first version of our new natural language querying interface, Query Assistant. We also talked a lot about the hard stuff we encountered when building and releasing this feature to all Honeycomb customers. But what we didn’t talk about was how we know how our use of an LLM is doing in production! That’s what this post is all about.
Ian Smith
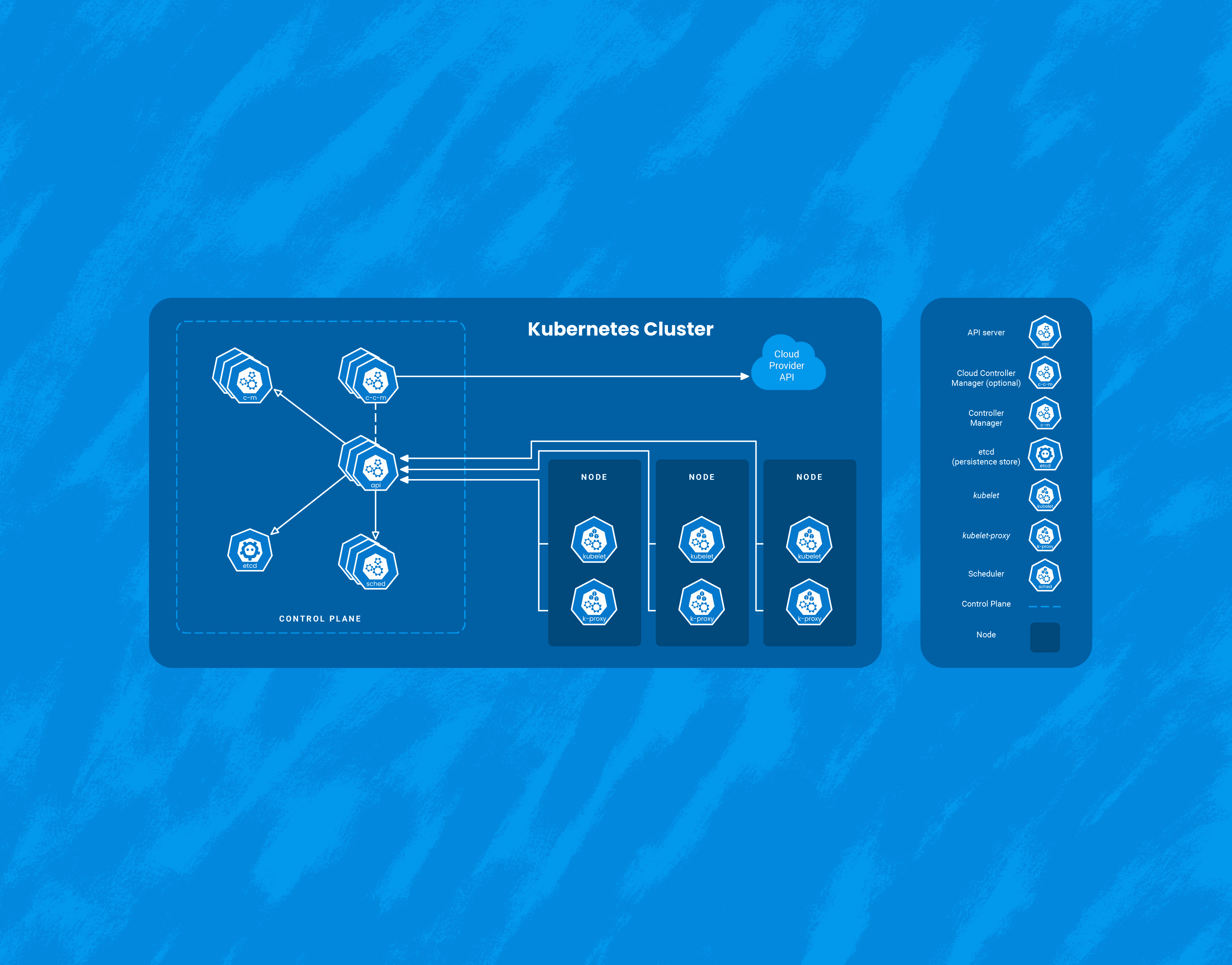
When considering a migration to Kubernetes, as with any major tech upgrade or change, it’s imperative to understand the motivation for doing so. The engineering time and labor to execute a complex migration will take away from other priorities, making it crucial to have org-wide alignment on why the change makes sense.
We saw a shift this year in how the technology sector honed in on sustainability from a cost perspective. In particular, looking at where they’re spending that revenue in the infrastructure and tooling space. Observability tooling comes under a lot of scrutiny as it’s perceived as a large cost center—and one that could be cut without affecting revenue. After all, if the business hasn’t had a problem in the last few months, we mustn’t need monitoring—right?
Nathan Lincoln
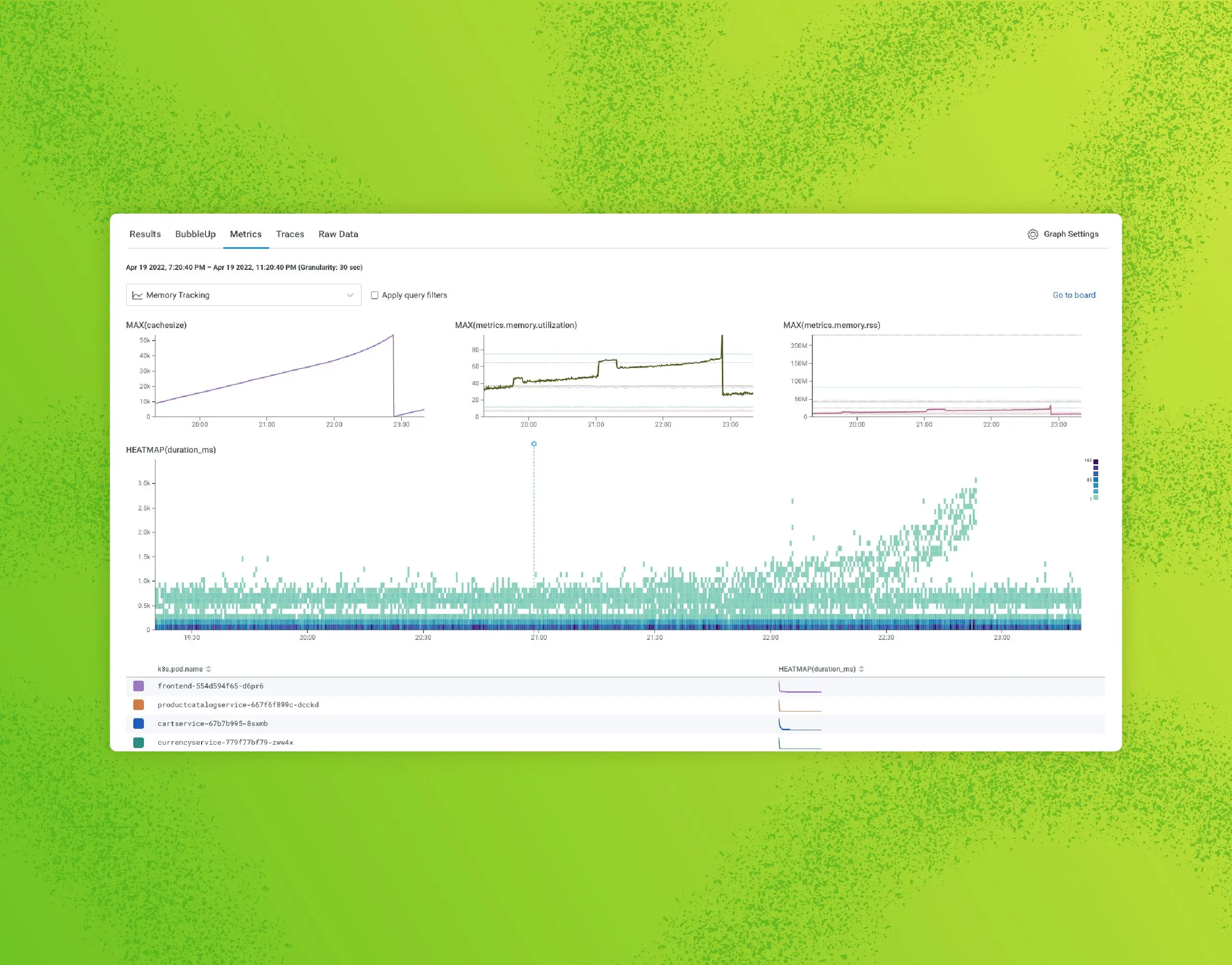
While Kubernetes comes with a number of benefits, it’s yet another piece of infrastructure that needs to be managed. Here, I’ll talk about three interesting ways that Honeycomb uses Honeycomb to get insight into our Kubernetes clusters. It’s worth calling out that we at Honeycomb use Amazon EKS to manage the control plane of our cluster, so this document will focus on monitoring Kubernetes as a consumer of a managed service.