Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Aiden Senner
The 1981 book Simulacra and Simulation by Jean Baudrillard is widely read and cited within academic circles but also permeates popular culture, influencing films, literature, and art. His theories notably influenced the Wachowski siblings’ The Matrix series, bringing some of his ideas into mainstream awareness.
Josephine Yuan
Expanded fields allow you to more easily find interesting traces and learn about the spans within them, saving time for debugging and enabling more curiosity within your team around how transactions perform throughout your services.
Austin Parker
You’re probably familiar with the concept of real user monitoring (RUM) and how it’s used to monitor websites or mobile applications. If not, here’s the short version: RUM requires telemetry data, which is generated by an SDK that you import into your web or mobile application. These SDKs then hook into the JS runtime, the browser itself, or various system APIs in order to measure performance. These SDKs are usually pretty optimized for both speed and size—you don’t want the dependency that tells you how fast or slow your application is to impact your application speed, after all.
Einar Norðfjörð
This article touches on how we at Birdie handled our transition from logs towards using OpenTelemetry as the primary mechanism for achieving world-class observability of our systems.
Jessica Kerr (Jessitron)
Today at Google Next, Charity Majors demonstrated how to use Honeycomb to find unexpected problems in our generative AI integration. Software components that integrate with AI products like Google’s Gemini are powerful in their ability to surprise us. Nondeterministic behavior means there is no such thing as “fully tested.” Never has there been more of a need for testing in production!
Howard Yoo
A few days ago, I was in a meeting with a prospect who was just starting to try out OpenTelemetry. One of the things that they did was to create an observability demo project which contained an HTTP reverse proxy, a web frontend, three microservices, a database, and a message queue.
Purvi Kanal
In a previous blog post, we outlined how to set up our own auto-instrumentation to send Core Web Vitals data to Honeycomb. We recently released a beta version of an OpenTelemetry wrapper to send traces from the browser to Honeycomb.
Winston Hearn
There’s a sentence that strikes fear into the heart of every frontend developer I’ve ever met: Users are reporting issues, and we don’t know how to replicate them. What do you do when that happens? Do you cry? Do you mark the issue as wontfix and move on? Personally, I took the road less traveled: gave up frontend engineering and moved into product management (this is not actually accurate but it’s a good joke and it feels truthy).
Rox Williams
We thought it’d be fun to give you some insights into what certain teams at Honeycomb do and how they spend their days, and who else would we start this experiment with than our fabulous customer success team? Without further ado, meet four of our bees!
Martin Thwaites
For years, we’ve been installing what vendors have referred to as “agents” that reach into our applications and pull out useful telemetry information from them. From monitoring agents, to full-blown APM tools, this has been the standard for many decades. With OpenTelemetry though, the term “agent” isn’t used as much, and in most scenarios means something slightly different. In this post, we’ll talk about the fact that you can achieve the same “hands off” process with OpenTelemetry, but also when you should and shouldn’t consider using the more automatic approach to telemetry collection.
Kate Guarente-Smith
We’re excited to unveil a new collaboration with Focused Labs, a leap forward in our shared commitment to advancing modern observability practices and enhancing the robustness of legacy systems. This partnership is not just about scaling our service offerings but also about integrating Focused Labs’ deep engineering expertise with our observability platform to deliver unparalleled customer experiences.
Naming things, and specifically consistently naming things, is still one of the most useful pieces of work you can do in telemetry. It’s often overlooked as something that will just happen naturally and won’t cause too much of an issue—but it doesn’t happen naturally, it does cause issues, and you end up having to fix the data in pipelines or your backend tool.
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
Chris Lasher
In this post, Chris describes how to send OpenTelemetry (OTel) data from an AWS Lambda instance to Honeycomb.
Fred Hebert
There are countless challenges around incident investigations and reports. Aside from sensitive situations revolving around blame and corrections, tricky problems come up when having discussions with multiple stakeholders. The problems I’ll explore in this blog—from the SRE perspective—are about time pressures (when to ship the investigation) and the type of report people expect.
Alex Boten
There is so much good work that OpenTelemetry has done in the software industry, specifically around the domain of observability, in the last five years. Bringing users and vendors together to define the future of telemetry? Check! Unify logs, traces, and metrics under a completely vendor-neutral API? Check! Deprecate other standards by bringing their collaborators to the table to ensure their use cases are met? CHECK!
In twenty years of software development, I did not have the privilege of being on call, of tending to my software in production. I’ve never understood what “APM” means. Anybody can tell me what it stands for—Application Performance Monitoring (or sometimes, the M means Management)—but what does it mean? What do people use APM for? Now, I work at an observability company—and still, no one can give me a satisfying definition of “APM.” So I did some research, and now the use of APM makes sense from a few angles.
Phillip Carter
Back in May 2023, I helped launch my first bona fide feature that uses LLMs in production. It was difficult in lots of different ways, but one thing I didn’t elaborate in several blog posts was how lucky I was to have a coherent way to get the data I needed to make the feature useful for users.
Jason Harley
We’re delighted to introduce our new Ingest API Keys, a significant step toward enabling all Honeycomb customers to manage their observability complexity simply, efficiently, and securely. Ingest Keys are currently available for Environment & Services customers, with Classic support and programmatic key management capabilities under development and coming soon!
In today’s economic and regulatory environment, data sovereignty is increasingly top of mind for observability teams. The rules and regulations surrounding telemetry data can often be challenging to interpret, leaving many teams in the dark about what kind of data they can capture, how long it can be stored, and where it has to reside.
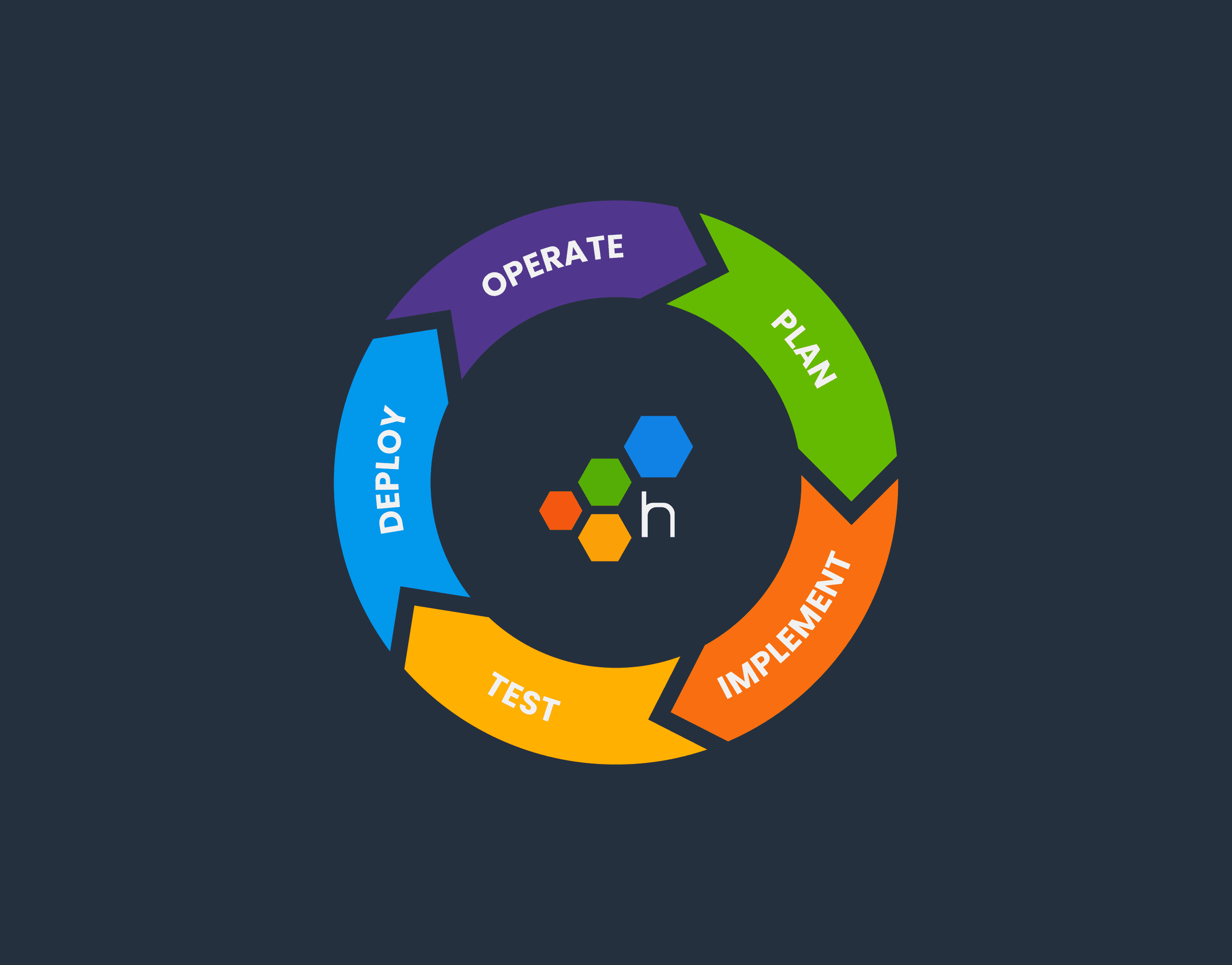
The software development lifecycle (SDLC) is always drawn as a circle. In many places I’ve worked, there’s no discernable connection between “5. Operate” and “1. Plan.” However, at Honeycomb, there is.