Honeycomb was built for the AI era. Learn how to futureproof your software for what comes next.
Discover why Honeycomb is the better choice for your engineers, your customers, and your bottom line.
Start your journey with the definitive guide to observability. Download our complimentary ebook.
Bring observability to every software engineer.
Learn about our company, mission and values.
Come for the impact, stay for the culture.
See Honeycomb's latest press releases, media, and more
Learn more about becoming a Honeycomb partner.
Already a Honeycomb customer?
Rebecca Carter
Distributed tracing enables you to monitor and observe requests as they flow through your distributed systems to understand whether these requests are behaving properly. You can compare tiny differences between multiple traces coming through your microservices-based applications every day to pinpoint areas that are affecting performance. As a result, debugging and troubleshooting are simpler and faster. No one has to guess or spend countless hours researching possible causes for issues, like you would if traditional logging methods were your only resource.
Fred Hebert
When I joined Honeycomb two years ago, we were entering a phase of growth where we could no longer expect to have the time to prevent or fix all issues before things got bad. All the early parts of the system needed to scale, but we would not have the bandwidth to tackle some of them graciously. We’d have to choose some fires to fight, and some to let burn.
Jessica McElroy
For a long time at Honeycomb, we envisioned using the tracing data you send us to generate a service map. If you’re unfamiliar, a service map is a graph-like visualization of your system architecture that shows all of its components and dependencies. We didn’t want it to be a static service map, though—the kind you’d view once before going “huh, neat”—and then never looking at it again. We wanted to build an actually useful, uniquely Honeycomb-y service map that could become an integral part of your team’s observability workflow.
Alyson van Hardenberg
In January 2022, Honeycomb kicked off a one year experiment to have an employee sit as a voting board member on the board of directors. I became that board member in July 2022. As the experiment comes to a close, I want to share some of my reflections.
Valerie Silverthorne
With one key practice, it’s possible to help your engineers sleep more, reduce friction between engineering and management, and simplify your monitoring to save money. No, really. We’re here to make the case that setting service level objectives (SLOs) is the game changer your team has been looking for.
Nick Travaglini
When an organization signs up for Honeycomb at the Enterprise account level, part of their support package is an assigned Technical Customer Success Manager. As one of these TCSMs, part of my responsibilities is helping a central observability team develop a strategy to help their colleagues learn how to make use of the product. At a minimum, this means making sure that they can log in, that relevant data is available, that they receive training on how to query, and perhaps that they collaborate with the rest of Honeycomb’s CS department to solve problems as they arise.
Sarrah Vesselov
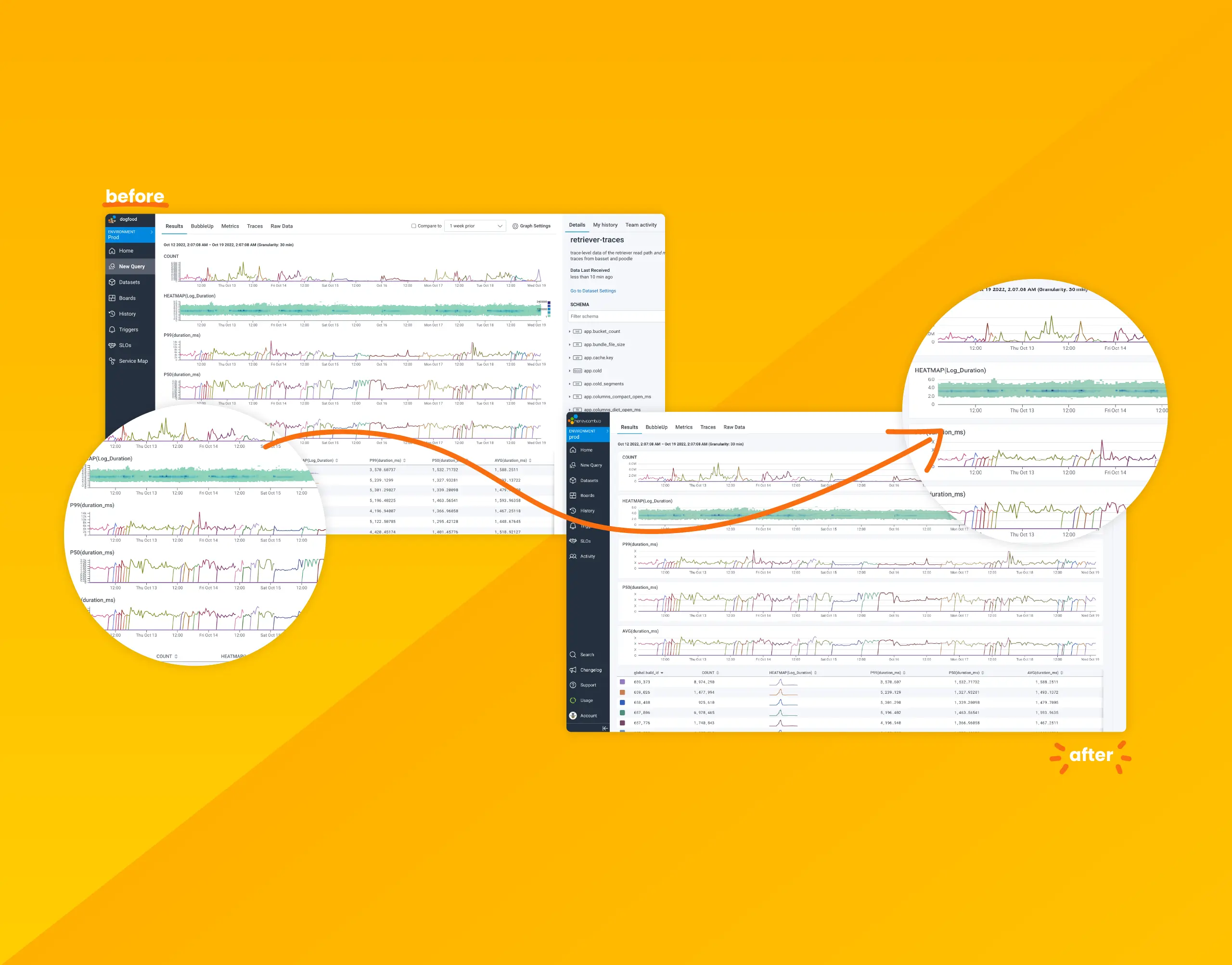
Over the past few months, we’ve been hard at work modernizing Honeycomb’s data visualizations to address consistency issues, confusing displays, access to settings, and to improve their overall look and feel.
Michael Wilde
Incidents happen. What matters is how they’re handled. Most organizations have a strategy in place that starts with log searches—and logs/log searching are great, but log searching is also incredibly time consuming. Today, the goal is to get safer software out the door faster, and that means issues need to be discovered and resolved in the most efficient way possible.
Mike Terhar
The best mechanism to combat proliferation of uncontrolled resources is to use Infrastructure as Code (IaC) to create a common set of things that everyone can get comfortable using and referencing. This doesn’t block the ability to create ad hoc resources when desired—it’s about setting baselines that are available when people want answers to questions they’ve asked in the past.
There are limits to what individuals or teams on the ground can do, and while counting fires or their acreage can be useful to know the burden or impact they have, it isn’t a legitimate measure of success. Knowing whether your firefighters or whether your prevention campaigns are useful can’t rely on these high-level observations, because they’ll be drowned in the noise of a messy unpredictable world.
Harrison Calato
George Miranda, Liz Fong-Jones, and Charity Majors, held a series of live discussions called the Authors’ Cut to bring core concepts of the book to life by applying them to real-world use cases. Now that the series is complete, we thought it would be helpful to combine all of the discussion recaps for your viewing pleasure. Each blog post below takes key concepts from chapters in the book and makes them more digestible.
Nick Rycar
We’re here to show you three ways you can jumpstart a distributed tracing effort, starting small and expanding as it makes sense. These examples involve only a little code and perhaps a bit of a mindset change. Starting small with distributed tracing can even be fun, because who doesn’t like getting customized results without much work?
Get it delivered straight to your inbox.
By subscribing to our newsletter, you agree to Honeycomb’s Terms of Service and Privacy Notice.
George Miranda
In this post, we’re moving from the foundations of observability to things that become critical when you start practicing observability at scale. Tools like sampling and telemetry pipelines are useful at any size, but when your trickle of observability data suddenly becomes a torrential flood, these tools are essential.
As 2022 draws to a close, the Honeycomb team is getting ready to take some time to recharge our collective batteries and get ready for the new year. For some of us, that means spending some well-earned time away from our keyboards. For others, it means we get to spend our computer time doing something just for fun.
Guest Blogger
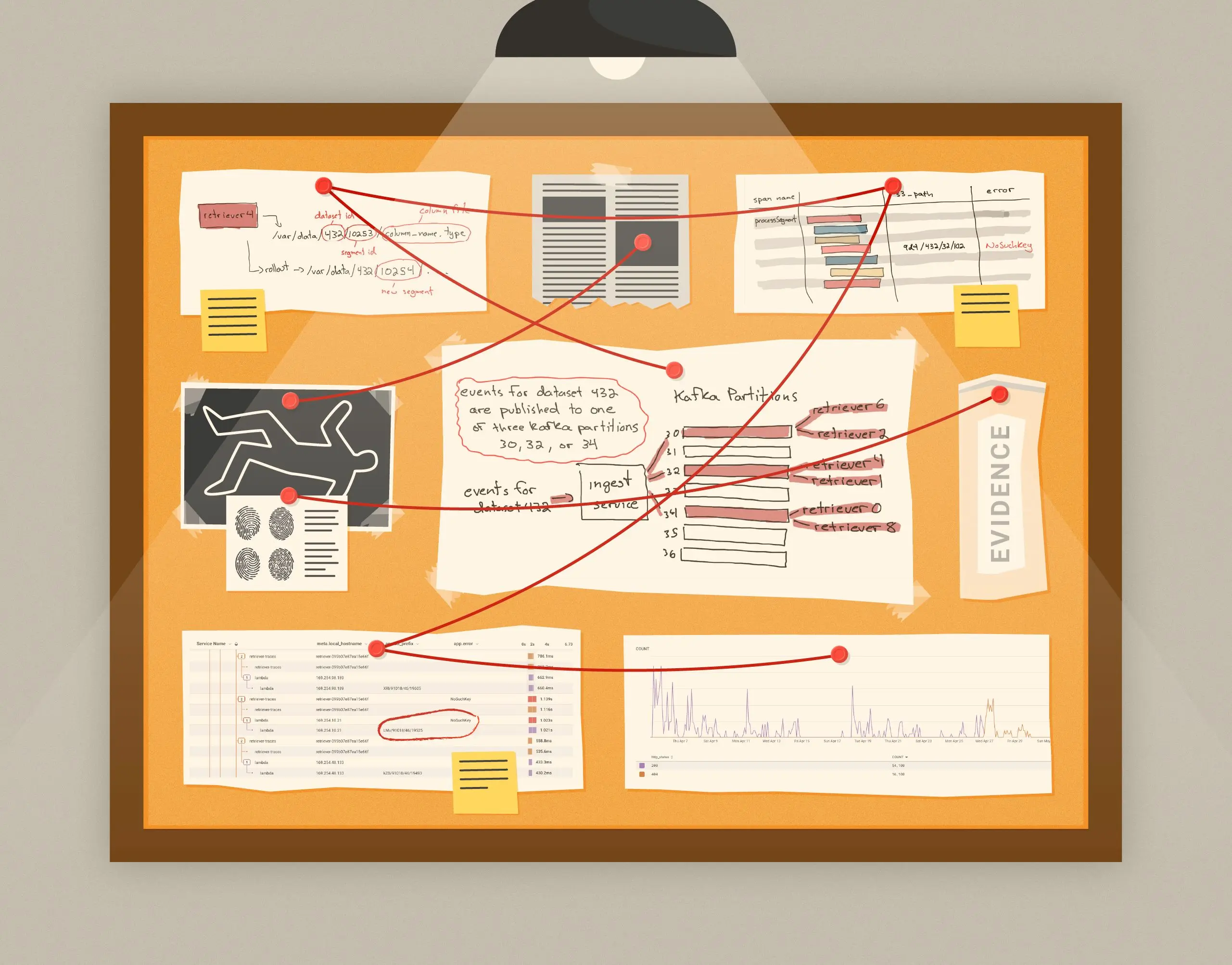
Bugs can remain dormant in a system for a long time, until they suddenly manifest themselves in weird and unexpected ways. The deeper in the stack they are, the more surprising they tend to be. One such bug reared its head within our columnar datastore in May this year, but had been present for more than two years before detection.
Today, we’re announcing the expansion of Honeycomb integrations with various AWS services. This update now covers a much wider swath of AWS services, makes it easier than ever to integrate your AWS stack with Honeycomb, and with our new BubbleUp enhancements, you’ll be identifying and debugging hidden issues in your AWS stack faster than ever.
Lex Neva
I joined Honeycomb as a Staff Site Reliability Engineer (SRE) midway through September, and it’s been a wild ride so far. One thing I was especially excited about was the opportunity to see Honeycomb’s incident retrospective process from the inside. I wasn’t disappointed!
Nathan Lincoln
With the introduction of Environments & Services, we’ve seen a dramatic increase in the creation of new datasets. These new datasets are smaller than ones created with Honeycomb Classic, where customers would typically place all of their services under a single, large dataset. This change has presented some interesting scaling challenges, which I’ll detail in this post, along with the solution we used, and how we leveraged Honeycomb’s own telemetry to scale Honeycomb.
If you’re writing software today, then you likely use a CI/CD pipeline to build and test your code before deploying it to production. Having a fast and efficient build pipeline saves you development time, shortens feedback loops, and helps you ship features faster. Conversely, slow and unreliable build pipelines are full of lost productivity and sadness.
In our Feature Focus October 2022, we’ve updated documentation and derived columns, provided guides to make CI/CD easier, and more.